
| August 16 & 17, 2019 | [ValleyML.ai] State of AI and ML-Summer 2019 |
| August 21, 2019 | 5G & Beyond: Perspectives on URLLC Vasuki Narasimha Swamy |
| Aug 29 to Oct 17, 2019 | [ValleyML.ai] Machine Learning and Deep Learning Boot Camp |
| June 14, 2019 | IEEE SPS MIVisionX Inference Tutorial |
In this tutorial, we will learn how to run inference efficiently using OpenVX and OpenVX Extensions. OpenVX is an open, royalty-free standard for cross platform acceleration of computer vision applications. It is designed by the Khronos Group to facilitate portable, optimized and power-efficient processing of methods for vision algorithms. The tutorial will go over each step required to convert a pre-trained neural net model into an OpenVX Graph and run this graph efficiently on any target hardware. In this tutorial, we will also learn about AMD MIVisionX which delivers open source implementation of OpenVX and OpenVX Extensions along with Neural Net Model Compiler & Optimizer.
| Tutorial Requirements: Install the appropriate terminal program on your laptop: Windows laptop – install MobaXterm – https://mobaxterm.mobatek.net/ Linux Laptop – install SSH – sudo apt install openssh-server Mac – install Xquartz – https://www.xquartz.org/ |
Intro | Tutorial |
 |
 |
| May 21, 2019 | Rethink Software Chris Doig |
| May 09, 2019 | Intelligent Ear-Level Devices for Hearing Enhancement and Health and Wellness Monitoring Tao Zhang, Ph.D., Director of Signal Processing Research Department, Starkey Hearing Technologies |
| May 01, 2019 | The future of lossy image compression: what machines can learn from humans Irena Fischer-Hwang |
| April 25, 2019 | Flexible Radios And Flexible Networks Dr. Alyssa Apsel, Cornell University |
| April 18, 2019 | Plasticine: A Reconfigurable Dataflow Architecture for Machine Learning/Software 2.0 Prof. Kunle Olukotun, Stanford University/SambaNova Systems |
Event Photos |
| April 11, 2019 | Enabling Wireless Autonomous Systems Using 5G Dr. Nageen Himayat, Intelligent Distributed Edge Networks Labs, Intel Corporation |
| March 20, 2019 | Quantization Noise Prof. Bernard Widrow, Stanford University |
| March 20, 2019 | Deep knockoffs machines for replicable selections Yaniv Romano |
| July 31, 2018 | Generative Adversarial Network and its Applications to Human Language Processing Professor Hung-Yi Lee, Assistant Professor of the Department of Electrical Engineering of National Taiwan University |
Generative adversarial network (GAN) is a new idea for training models, in which a generator and a discriminator compete against each other to improve the generation quality. Recently, GAN has shown amazing results in image generation, but the applications of GAN on text and speech processing are still limited. In this talk, I will demonstrate the applications of GAN on unsupervised abstractive summarization and sentiment controllable chat-bot. I will also talk about the research directions towards unsupervised speech recognition by GAN.
| July 19, 2018 | Review of LiDAR, Localization and Object Processing for Safe Autonomous Systems Dr. Kiran Gunnam, Distinguished Engineer, Western Digital |
| June 7, 2018 | LiDAR training data best practices Mohammad Musa, Founder and CEO at Deepen AI |
Accurate LiDAR classification and segmentation is required for developing critical ADAS and Autonomous Vehicles components. Mainly, its required for high definition mapping and developing perception and path/motion planning algorithms. This talk will cover best practices for how to accurately annotate and benchmark your AV/ADAS models against LiDAR ground truth training data.
| May 17, 2018 | Augmenting Cognition through Data Visualization Alark Joshi, Associate Professor in the Department of Computer Science at the University of San Francisco |
| May 1, 2018 | Small, Medium, and Big Data: Application of Machine Learning Methods to the Solution of Real-World Imaging and Printing Problems Jan P. Allebach, Hewlett-Packard Distinguished Professor of Electrical and Computer Engineering, Purdue University |
Slides |
To provide a context for the discussion to follow, I will first briefly discuss the general characteristics of machine learning. Then, I will describe a series of problems that illustrate the successful application of machine learning methods to the solution of problems in the printing and imaging space. These problems range from the development of detailed microscale models for printer behavior; to algorithms for print and image quality assessment; to algorithms for predicting aesthetic quality of fashion photographs; to algorithms for detection and recognition of people in home and office settings. The algorithms take a variety of different forms ranging from linear regression, context-dependent linear regression, and context-dependent linear regression augmented by stochastic sample function generation; to maximum likelihood estimation; to support vector machines; to convolutional neural networks. The size of the data sets used to train these algorithms range from tens of images to tens of thousands of images.
| Apr 11, 2018 | Computer Vision at the Edge and in the Cloud: Architectures, Algorithms, Processors, and Tools Jeff Bier, Founder, Embedded Vision Alliance and President, BDTI |
Slides |
Computer vision is rapidly becoming ubiquitous. From autonomous robots, vehicles and drones to smart buildings to home assistants that can advise you on your fashion choices, vision is showing up everywhere. A key architectural choice underlies this ubiquity: should vision processing be done at the edge, in the cloud, or a hybrid combination of the two? Jeff Bier, Founder of the Embedded Vision Alliance, will discuss the benefits and trade-offs of edge, cloud, and hybrid models, and when you should consider each option. Within this edge-cloud framework, Jeff will also provide an update on important recent developments in the technologies enabling vision, including processors, sensors, algorithms, development tools, services and standards. Jeff will also highlight some of the most interesting and most promising end-products and applications incorporating vision capabilities.
| Mar 15, 2018 | 50 Years of Computer Architecture: From Mainframe CPUs to DNN TPUs and Open RISC-V Prof. David Patterson, Google, Mountain View, CA, University of California, Berkeley, CA |
| Mar 12, 2018 | An Exciting Course Ahead in Signal Processing Chandrakant D. Patel, HP Senior Fellow and Chief Engineer |
The 21st century cyber physical age is about the seamless integration of cyber and physical systems. The growth of cyber physical systems is motivated by the need to address the challenges stemming from the socio-economic megatrends such as population increase, changing demographics, rapid urbanization and resource constraints. Cyber physical applications – from healthcare and factories to city scale supply side infrastructure such as power, water, waste, transport – present an exciting opportunity to the signal processing community. With respect to cyber-physical signal processing applications, the key to success lies in taking the learning from today, image signal processing as an example, in combination with the signal processing of the machine age centered around domain knowledge.
Signal processing in the 1980s was about availing structured data streams from physical systems, and using various instruments and analysis techniques, to infer and acting upon the data. The workflow often began with an understanding of the domain – dynamics of physical structures as an example – and running experiments to prove or disprove a hypothesis. In the latter part of 20 th century cyber age, the rise of image processing hardware and the ability to manage large amounts of data, led to exciting advancements in learning from data from visual systems. In this talk, I will make the case that cyber physical systems of tomorrow will require us to take a holistic perspective covering domain knowledge, design and topology associated with computing hardware, together with data mining and knowledge discovery.
We will have to leverage our past to create the future.
| Mar 8, 2018 | Running Sparse and Low-Precision Neural Networks: An Interactive Play between Software and Hardware Hai “Helen” Li, Associate Professor, Department of Electrical and Computer Engineering, Duke University |
| Feb 07, 2018 | Building Intuition into Adversarial Examples in Deep Learning Dr. Simant Dube, AI Winning Solutions |
In recent years, deep neural networks have found wide ranging applications in the general field of AI. However, it has been shown that deep learning suffers from Adversarial Examples which have puzzled AI scientists. For acceptance of deep learning based AI solutions, it is important to understand this intriguing phenomenon and to eliminate it. Furthermore, there has been debate in social media about urgent need to bring rigor to the field of deep learning. Inspired by that, in this talk, we present novel results which explain adversarial examples in Computer Vision and which also pave way for future progress in AI.
| Dec 09, 2017 | Walk with IEEE Fellows Stanford Dish Loop Trail, meet at the first intersection close to Stanford Ave entrance |
This December, we are hosting a “Walk with IEEE Fellows” event, and would love to sincerely invite you to join us for a walk in the Stanford Dish Loop Trail. While getting exercise, this is a great opportunity to connect with local IEEE Fellows and members, share insights, and get inspired. Located right next to the Stanford campus, the heart of Silicon Valley, Stanford Dish Loop Trail gets nice and green in winter. From certain locations, you get to overlook the whole Stanford campus and San Francisco Bay.
 |
 |
| Dec 4, 2017 | Deep Learning in Biomedicine and Genomics Dr. Mark DePristo, Google |
| Nov 16-17, 2017 | IEEE Artificial Intelligence Symposium Santa Clara, CA |
| Nov 1, 2017 | Learning with limited supervision Dr. Stefano Ermon, Stanford University |
| Sep 26, 2017 | Hebbian Learning and the LMS Algorithm Prof. Bernard Widrow, Department of Electrical Engineering, Stanford University |
Hebb’s learning rule can be summarized as “neurons that fire together wire together.” Wire together means that the weight of the synaptic connection between any two neurons is increased when both are firing. Hebb’s rule is a form of unsupervised learning. Hebb introduced the concept of synaptic plasticity, and his rule is widely accepted in the field of neurobiology.
When imagining a neural network trained with this rule, a question naturally arises. What is learned with “fire together wire together,” and what purpose could this rule actually have? Not having a good answer has long kept Hebbian learning from engineering applications. The issue is taken up here and possible answers will be forthcoming. Strictly following Hebb’s rule, weights could only increase, never decrease. This would eventually cause all weights to saturate, yielding a useless network. When extending Hebb’s rule to make it workable, it was discovered that extended Hebbian learning could be implemented by means of the LMS algorithm. The result was the Hebbian-LMS algorithm.
The LMS (least mean square) algorithm was discovered by Widrow and Hoff in 1959, ten years after Hebb’s classic book first appeared. The LMS algorithm optimizes with gradient descent. It is the most widely used learning algorithm today. It has been applied in telecommunications systems, control systems, signal processing, adaptive noise cancelling, adaptive antenna arrays, etc. It is at the foundation of the backpropagation algorithm of Paul Werbos. Hebb’s rule notwithstanding, the nature of the learning algorithm(s) that adapt and control the strength of synaptic connections in animal brains is for the most part unknown. The biochemistry of synaptic plasticity is largely understood, but the overall control algorithm is not understood. A solution to this mystery might be the Hebbian-LMS algorithm, a control process for unsupervised training of neural networks that perform clustering. Considering the structure of neurons, synapses, and neurotransmitters, the electrical and chemical signals necessary for the implementation of the Hebbian-LMS algorithm seem to be all there. Hebbian-LMS seems to be a natural algorithm. It is proving to be a simple useful algorithm that is easy to make work. Neuron to neuron connections are as simple as can be. All this raises a question. Could a brain or major portion of a brain be implemented with basic building blocks that perform clustering? Is clustering nature’s fundamental neurological building block?
On the engineering side, layered neural networks trained with Hebbian-LMS have been simulated. Hidden layers are trained, unsupervised, with Hebbian-LMS while the output layer is trained with classic LMS, supervised. The hidden layers perform clustering. The output layer is fed clustered inputs, and from this makes the final classification decisions. Networks that are not layered, for example randomly connected, can be implemented with Hebbian-LMS neurons to provide inputs to an output classifier. The same training algorithm could be utilized. The Hebbian-LMS network is a general purpose trainable classifier and gives performance comparable to a layered network trained with the backpropagation algorithm. The Hebbian-LMS network is much simpler to implement and easier to make work. It is early to predict, but it seems highly likely that Hebbian-LMS will have many engineering applications to clustering, pattern classification, signal processing, control systems, and to machine learning.
| Sep 21, 2017 | Vision and the Deep Learning Explosion Dr. Chris Rowen, CEO, Cognite Ventures and Stanford University |
Everyone sees the excitement about artificial intelligence, but what’s real? Everyone gets pumped up about smart drones and self-driving cars, but what does it take to really harness the potential of deep learning for real products? The academic benchmarks are impressive, but how does research translate into break-out businesses? Why is computer vision embracing deep neural networks so passionately?
This talk looks closely at artificial intelligence aka deep learning aka neural network aka cognitive computing technologies, maps out the affected applications and industries and dives into the profound impact it is having one example segment, computer vision. It explores the relationship among vision research, cloud and embedded AI product opportunities and the global explosion in the number of deep learning startups. Finally, it sketches some of the most important principles that successful startups are following to succeed in the frothy, frenetic and fascinating entrepreneurial game.
| Aug 31, 2017 | Khronos Standards for Neural Network Acceleration and Deployment Radhakrishna Giduthuri, AMD |
Slides |
Khronos Group is a not for profit, member-funded consortium to create royalty-free open standards for hardware acceleration. OpenVX is an API for computer vision and neural network acceleration, especially important in real-time and safety-critical use cases. Khronos Group is also readying NNEF standard interchange format to transfer networks trained in deep learning frameworks to optimized inference engines. This talk gives an overview of Khronos standards related to neural networks and computer vision. A set of examples for neural networks and computer vision mapped to graph API will also be discussed.
| Aug 01, 2017 | Video codec standardization update for 360 degree video Jill Boyce, Intel |
Slides |
MPEG and ITU-T VCEG are developing new SEI messages for HEVC to standardize coding of omnidirectional spherical video (also called 360° video”), for inclusion in a new version of HEVC in late 2017. These SEI messages can be used with existing HEVC profiles, with projection mapping of the spherical video into a 2D rectangular format. New methods of objective and subjective testing for 360° video have been developed to study the impact of different projection formats on coding efficiency and video quality. The MPEG/VCEG Call for Evidence for a new video coding standard with capability beyond HEVC (e.g. a future H.266), includes a category for 360° video, and allows new specifically targeted coding tools.
 |
 |
 |
| Jun 22, 2017 | Computational Microscopy Prof. Laura Waller, UC Berkeley |
Slides |
Computational imaging involves the joint design of imaging system hardware and software, optimizing across the entire pipeline from acquisition to reconstruction. This talk will describe new methods for computational microscopy with coded illumination, based on a simple and inexpensive hardware modification of a commercial microscope, combined with advanced image reconstruction algorithms. In conventional microscopes and cameras, one must trade off field-of-view and resolution. Our methods allow both simultaneously by using multiple images, resulting in Gigapixel-scale reconstructions with resolution beyond the diffraction limit of the system. Our algorithms are based on large-scale nonlinear non-convex optimization procedures for phase retrieval, with appropriate priors.
Visit laurawaller.com for related publications and projects
 |
 |
 |
| May 16, 2017 | A Universal Low-latency Real-time Optical Flow based Stereoscopic Panoramic Video Communication System for AR/VR Dr. Jiangtao Wen, Tsinghua University |
Slides |
Introduce an optimized system for real time, low latency stereoscopic panoramic video communications that is camera agnostic. After intelligent camera calibration, the system is capable of stitching inputs from different cameras using a real time, low latency optical flow based algorithm that intelligently learns input video features over time to improve stitch quality. Depth information is also extracted in the process. The resulted stereoscopic panoramic video is then encoded with content-adaptive temporal and/or spatial resolution to achieve low bitrate while maintaining good video quality. Various aspects of the system including the optimized stitching algorithm, parallelization and task scheduling, as well as encoding will be introduced with demos with conventional (non-panoramic) professional and consumer grade cameras as well as integrated panoramic cameras.
 |
 |
| Apr 06, 2017 | New immersive and object-based multichannel audio formats for cinema, entertainment and cinematic VR Dr. Jean-Marc Jot, Senior VP, R&D, DTS Inc. |
Slides |
In recent years, several audio technology companies and standardization organizations (including Dolby, Auro, DTS, MPEG) have developed new formats and tools for the creation, archiving and distribution of immersive audio content in the cinema or broadcast industries. These developments extend legacy multi-channel audio formats to support three-dimensional (with height) sound field encoding, along with optional audio object channels accompanied with positional rendering metadata. They enable efficient content delivery to consumer devices and flexible reproduction in multiple consumer playback environments, including headphones and frontal audio projection systems. In this talk, we’ll review and illustrate the state of these developments and discuss perspectives and pending issues, including virtual reality applications.
| Mar 23, 2017 | Deep Learning in Siri Dr. Alex Acero, Apple. |
Siri, Apple’s personal assistant, first shipped in 2011 as part of iOS and brought conversational agents into the mainstream. Users can access Siri from their iPhone, iPad, Apple Watch, AppleTV and Carplay in 21 languages. Deep learning has revolutionized the field of machine learning, making a big impact in both core algorithms and application areas like speech recognition, critical for Siri. Mixture Density Networks, a particular type of deep learning, now power Apple’s TTS engine, making Siri’s voices more natural, smoother, and allowing Siri’s personality to shine through. Accented speech, always a challenge for speech recognition systems, can be addressed by training deep neural networks and convolutional neural networks with various sources of data properly weighted in order to achieve a robust acoustic model.
 |
 |
 |
| Feb 22, 2017 | Localizing the Epileptic Seizure Onset Zone via Directed Information Graphs Dr. Yonathan Morin, Stanford University |
Epilepsy is one of the most common neurological disorders affecting about 1% of the world population. While in most cases treating epilepsy with antiepileptic drugs (AED) is successful, about a third of the patients cannot be adequately treated with AEDs. The main treatment for such patients is a surgical procedure for removal of the seizure onset zone (SOZ), the area in the brain from which the seizures originate. The main tool for accurately identifying the SOZ is electrocorticography (ECoG) recordings, taken from grids of electrodes placed on the cortex to allow a direct measurement of the brain’s electric activity. In this talk we will present a novel SOZ localization algorithm, based on ECoG recordings. Our underlying hypothesis is that seizures start in the SOZ and then spread to surrounding areas in the brain. Thus, signals recorded at electrodes close to the SOZ should have a relatively large causal influence on the rest of the recorded signals. To evaluate the statistical causal influence between the recorded signals, we represent the set of electrodes using a directed graph, where the edges’ weights are the pair-wise causal influence, quantified via the information theoretic functional of directed information. The directed information is estimated from the ECoG recording using the nearest-neighbor estimation paradigm. Finally, the SOZ is inferred from the obtained network via a variation of the famous PageRank algorithm. Testing the proposed algorithm on 15 ECoG recordings of epileptic patients, listed in the iEEG portal, shows a close match with the SOZ estimated by expert neurologists.
| Feb 9, 2017 | Unsupervised Machine Learning: Application to Data Fusion Prof. Tülay Adali, Dept. of CSSE, University of Maryland Baltimore County |
Fusion of information from multiple sets of data in order to extract a set of features that are most useful and relevant for the given task is inherent to many problems we deal with today. Data-driven methods based on source separation minimize the assumptions about the underlying relationships and enable fusion of information by letting multiple datasets to fully interact and inform each other. Use of multiple types of diversity – statistical property – enables maximal use of the available information when achieving source separation. In this talk, a number of powerful models are introduced for fusion of both multiset – data of the same nature – as well as multi-modal data, and the importance of diversity in fusion is demonstrated with a number of practical examples in medical imaging and video processing.
 |
 |
| Jan 27, 2017 | Bowling with IEEE Young Professionals IEEE Santa Clara Valley Young Professionals |
| Jan 20, 2017 | Deep Learning for Image and Video Processing Jonathon Shlens & George Toderici, Google Research |
Deep learning has profoundly changed the field of computer vision in the last few years. Many computer vision problems have been recast with techniques from deep learning and in turn achieved state of the art results and become industry standards. In this tutorial we will provide an overview about the central ideas of deep learning as applied to computer vision. In the course of this tutorial we will survey the many applications of deep learning to image and video problems. The goal of this tutorial is to teach the central and core ideas and provide a high level overview of how deep learning has influenced computer vision.
| Dec 13, 2016 | Super-resolution Image Reconstruction – Methods and Lessons Learned Prof. Sally Wood, Thomas J. Bannan Professor in Electrical Engineering, Santa Clara University |
Although there is some variation in the interpretation of the term “super-resolution” in different imaging application contexts, for computational methods it typically refers to the use of multiple images acquired at a low spatial resolution to compute a single image with increased spatial resolution. The motivation for this may be to improve the perceptual quality of the image content or to derive more accurate information from the image content such as the location of features. This may be attractive in situations where a higher resolution camera can not be used because of size or cost for example. A potential application, which may be fixed or mobile, is monitoring and surveillance. The additional information used to improve the spatial resolution may be some combination of a-priori assumptions and multiple passively acquired images in which the desired high frequency information is present, but aliased. Performance measures of super-resolution algorithms may be based on measures of image accuracy, measures of image quality, computational efficiency, or robustness in the presence of measurement noise and image acquisition model error. While computational efficiency is relatively unambiguous, the metrics for accuracy and robustness may be debated. This talk will provide an introduction to super-resolution methods and applications, explore the effects of noise and model error on resolution improvement, describe one specific project application, and discuss general lessons learned.
| Nov 03, 2016 | The Soul of a New Camera: The Design of Facebook’s Surround Open Source 3D-360 Video Camera Brian Cabral, Director of Engineering, Facebook |
Around a year ago we set out to create an open-source reference design for a 3D-360 camera. In nine months, we had designed and built the camera, and published the specs and code. Our team leveraged a series of maturing technologies in this effort. Advances and availability in sensor technology, 20+ years of computer vision algorithm development, 3D printing, rapid design proto-typing and computational photography allowed our team to move extremely fast. We will delve into the roles each of these technologies played in the designing of the camera, giving an overview of the system components and discussing the tradeoffs made during the design process. The engineering complexities and technical elements of 360 stereoscopic video capture will be discussed as well. We will end with some demos of the system and its output.
| Oct 20, 2016 | [Distinguished Lecturer] Demystifying Linear Time Varying Circuits Prof. Shanthi Pavan, Indian Institute of Technology-Madras |
| Oct 06, 2016 | Indoor and Outdoor Image based Localization for mobile devices Prof. Avideh Zakhor, EECS Department, UC Berkeley and Indoor Reality |
Image geo-location has a wide variety of applications in GPS denied environments such as indoors, as well as error prone outdoor environments where GPS signal is unreliable. Besides accuracy, an inherent advantage of image based localization is recovery of orientation as well as position. This could be important in applications such as navigation and augmented reality. In this talk, I describe a number of indoor and outdoor image based localization approaches and characterize their performance in a variety of scenarios. I start with a basic divide and conquer photo-matching strategy for large area outdoor localization and show its superior performance over compass and GPS on today’s cell phones; I characterize the performance of this system for a 30,000 image database for Oakland, CA as well as 5 million image database for 10,000 square km area in Taiwan. Next I describe a fast, automated methodology for Simultaneous Multi-modal fingerprinting And Physical mapping (SMAP) of indoor environments to be used for indoor positioning. The sensor modalities consist of images, WiFi and magnetic. I show that one shot, static image based localization has 50 percentile error of less than 1 meter and 85 percentile error of less than 2 meters. Finally, I describe the associated multi-modal indoor positioning algorithms for dynamic tracking of users and show that they outperform uni-modal schemes based on WiFi alone. Future work consists of demonstrating the scheme on wearable devices such as the Glass, and the Watch.
| Sep 22, 2016 | When Machine Learning Takes over Audio Signal Processing [Distinguished Lecturer] Prof. Paris Smaragdis, University of Illinois at Urbana-Champaign |
During the last few years, machine learning has started to permeate the world of audio processing and has produced results that drastically improve over the state of the art. In this talk I’ll touch on some recent approaches taking advantage of a machine learning perspective for attacking audio problems. I will show how traditional signal processing approaches can be reimagined using machine learning tools such as mixture models, matrix factorizations, deep learning regressions, and more.
| Aug 25, 2016 | Learning Sparsifying Transforms for Signal, Image, and Video Processing [Distinguished Lecturer] Prof. Yoram Bresler, University of Illinois at Urbana-Champaign |
The sparsity of signals and images in a certain transform domain or dictionary has been exploited in many applications in signal and image processing, including compression, denoising, and notably in compressed sensing, which enables accurate reconstruction from undersampled data. These various applications used sparsifying transforms such as DCT, wavelets, curvelets, and finite differences, all of which had a fixed, analytical data-independent form. Recently, sparse representations that are directly adapted to the data have become popular, especially in applications such as image and video denoising and inpainting. While synthesis dictionary learning has enjoyed great popularity and analysis dictionary learning too has been explored, these methods involve a repeated step of sparse coding, which is NP hard, and heuristics for its approximation are computationally expensive. In this talk we describe our work on an alternative approach: sparsifying transform learning, in which a sparsifying transform is learned from data. The method provides efficient computational algorithms with exact closed-form solutions for the alternating optimization steps, and with theoretical convergence guarantees. The method scales better than dictionary learning with problem size and dimension, and in practice provides orders of magnitude speed improvements and better image quality in image processing applications. Variations on the method include the learning of a union of transforms, and online versions. We describe applications to image representation, image and video denoising, and inverse problems in imaging, demonstrating improvements in performance and computation over state of the art methods.
| Aug 18, 2016 | Enabling and Exploiting Machine Learning in Ultra-low-power Devices [Distinguished Lecturer] Prof. Naveen Verma, Princeton University |
| Jun 16, 2016 | Convolutional neural network models of the first stages in biological vision Lane McIntosh, Neurosciences PhD candidate, Stanford University |
In order to understand how and why biological vision pathways perform particular computations, we must first know what they do. The first stages of biological vision occur in the retina, and consist of cascaded nonlinear processes like synaptic transmission and spiking dynamics that compress the entire visual scene into the sparse responses of only one million spiking cells. The ubiquity of these dynamic, nonlinear computations in the retina have presented significant obstacles to the goal of learning accurate computational models of circuit responses to natural stimuli from neural recordings. In this talk I will discuss recent work demonstrating that convolutional neural networks (CNNs) are considerably more accurate at capturing retinal responses to held-out natural scenes stimuli than pre-existing published models of the retina. Moreover, we find CNNs generalize significantly better across classes of stimuli they were not trained on. Remarkably, analysis of these CNNs reveals internal units selective for visual features on the same small spatial scale as the main excitatory interneurons of the retina, bipolar cells. Overall, this work demonstrates the power of CNNs to not only accurately capture sensory circuit responses to natural scenes, but also uncover the circuit’s internal structure and function.
| Jun 09, 2016 | Noncoherent communications in large antenna arrays Mainak Chowdhury, PhD Candidate, Wireless Systems Laboratory, Stanford University |
Coherent schemes with accurate channel state information are considered to be important to realizing many benefits from massive multiple-input multiple-output (massive MIMO) cellular systems involving large antenna arrays at the base station. In this talk we introduce and describe noncoherent communication schemes, i.e., schemes which do not use any instantaneous channel state information, and find that they have the same scaling behavior of achievable rates as coherent schemes with the number of antennas. This holds true not only for Rayleigh fading, but also for ray tracing models. Analog signal processing architectures for large antenna arrays based on our analyses will be described. We also consider wideband large antenna systems and identify a bandwidth limited regime where having channel state information does not increase scaling laws, and outside of which there is a clear rate penalty. This talk is based on joint work with Alexandros Manolakos, Andrea Goldsmith, Felipe Gomez-Cuba, and Elza Erkip.
| May 12, 2016 | Neural Interfaces and How They Use Signal Processing Dr. Sarah Felix, Independent Consultant |
A neural interface is an engineered system that interacts with nerves to study, repair, or enhance the function of the nervous system. Examples that may be familiar are cochlear implants, deep brain stimulation, and EEG brain sensors. More advanced systems are currently in development for closed-loop brain modulation and robotic limb control. Developing neural interfaces involves many disciplines including computational neuroscience, biology, microtechnology, electronics packaging, medicine, and…signal processing! Various classes of signal processing problems arise, from detection to decoding, from filtering to feature extraction. In this talk I hope to expand the audience’s awareness of this exciting field by presenting a sampling of advanced neural interface applications and highlighting signal processing challenges at the heart of emerging therapeutic technologies.
| May 10, 2016 | The Search for Extraterrestrial Intelligence at the SETI Institute Dr. Gerald (Gerry) R. Harp, SETI Institute |
SETI Institute is a non-profit research institute in Mountain View, CA and is a world leader in all topics pertaining to the evolution of life in the universe, from interstellar chemistry, to extremophiles on Earth, to the discovery of exoplanets, to the radio search for extraterrestrial intelligence. I will discuss the physical arguments in favor of radio SETI, and describe the state of the art for SETI observations to date. The most important challenge for radio SETI at this time is the pervasive presence of human-generated signals that trigger false positives in our SETI detectors. The only reliable weapon to combat such interference is direction-of-arrival estimation that can prove a signal originates from outer space. I give a description of the most advanced digital signal processing technologies in use or being developed for the ETI search including direction-of-arrival estimation and detection of technological signals with arbitrary waveforms. Future observations with the Square Kilometer Array will propel the radio ETI search into a new domain of sensitivity and direction-of-arrival estimation.
| Apr 27, 2016 | New Approaches to Haptics for Teleoperation and Virtual Reality Samuel B. Schorr, PhD Candidate, Stanford University |
| Apr 06, 2016 | A Signal-Processing Approach to Modeling Vision, and Applications Prof. Sheila S. Hemami, Northeastern University |
Current state-of-the-art algorithms that process visual information for end use by humans treat images and video as traditional signals and employ sophisticated signal processing strategies to achieve their excellent performance. These algorithms also incorporate characteristics of the human visual system (HVS), but typically in a relatively simplistic manner, and achievable performance is reaching an asymptote. However, large gains are still realizable with current techniques by aggressively incorporating HVS characteristics to a much greater extent than is presently done, combined with a good dose of clever signal processing. Achieving these gains requires HVS characterizations which better model natural image perception ranging from sub-threshold perception (where distortions are not visible) to suprathreshold perception (where distortions are clearly visible). In this talk, I will review results from our lab characterizing the responses of the HVS to natural images, and contrast these results with ‘classical’ psychophysical results. I will also present several examples of signal processing algorithms which have been designed to fully exploit these results.
| Apr 01, 2016 | OpenVX: A Framework for Accelerating Computer Vision [Tutorial] Kari Pulli (Intel), Radhakrishna Giduthuri (AMD), Thierry Lepley (NVIDIA) |
OpenVX is a royalty-free open standard API released by the Khronos Group in 2014. OpenVX enables performance and power-optimized computer vision functionality, especially important in embedded and real-time use cases. The course covers both the function-based API and the graph API that enable OpenVX developers to efficiently run computer vision algorithms on heterogeneous computing architectures. A set of example algorithms from computational photography and advanced driver assistance mapped to the graph API will be discussed. Also covered is the relationship between OpenVX and OpenCV, as well as OpenCL. The tutorial includes hands-on practice session that gets the participants started on solving real computer vision problems using OpenVX. Learning Outcomes: Understanding the architecture of OpenVX computer vision API, its relation to OpenCV, OpenGL, and OpenCL APIs; getting fluent in actually using OpenVX for real-time image processing and computer vision tasks.
| Mar 23, 2016 | When Your Big Data Seems Too Small: Accurate inferences beyond the empirical distribution Prof. Gregory Valiant, Stanford |
We discuss two problems related to the general challenge of making accurate inferences about a complex distribution, in the regime in which the amount of data (i.e the sample size) is too small for the empirical distribution of the samples to be an accurate representation of the underlying distribution. The first problem is the basic task of inferring properties of a discrete distribution, given access to independent draws. We show that one can accurately recover the unlabelled vector of probabilities of all domain elements whose true probability is greater than 1/(n log n). Stated differently, one can learn–up to relabelling–the portion of the distribution consisting of elements with probability greater than 1/(n log n). This result has several curious implications, including leading to an optimal algorithm for “de-noising” the empirical distribution of the samples, and implying that one can accurately estimate the number of new domain elements that would be seen given a new larger sample, of size up to n* log n. (Extrapolation beyond this sample size is provable information theoretically impossible, without additional assumptions on the distribution.) While these results are applicable generally, we highlight an adaptation of this general approach to some problems in genomics (e.g. quantifying the number of unobserved protein coding variants).
The second problem we consider is the task of accurately estimating the eigenvalues of the covariance matrix of a (high dimensional real-valued) distribution–the “population spectrum”. (These eigenvalues contain basic information about the distribution, including the presence or lack of low- dimensional structure in the distribution and the applicability of many higher- level machine learning and multivariate statistical tools.) As we show, even in the regime where the sample size is linear or sublinear in the dimensionality of the distribution, and hence the eigenvalues and eigenvectors of the empirical covariance matrix are misleading, accurate approximations to the true population spectrum are possible. This talk is based on three papers, which are joint works with Paul Valiant,James Zou, and Weihao Kong.
| Mar 03, 2016 | First-Photon Imaging and Other Imaging with Few Photons Dr. Vivek Goyal, Associate Professor, Boston University |
LIDAR systems use single-photon detectors to enable long-range reflectivity and depth imaging. By exploiting an inhomogeneous Poisson process observation model and the typical structure of natural scenes, first-photon imaging demonstrates the possibility of accurate LIDAR with only 1 detected photon per pixel, where half of the detections are due to (uninformative) ambient light. I will explain the simple ideas behind first-photon imaging. Then I will present related subsequent works that enable the use of detector arrays and improve robustness to ambient light.
| Feb 25, 2016 | Developing Successful Career Relationships: Leveraging Mentoring, Coaching, and Sponsorship Sarah Kalicin, Senior Statistician, Intel Corporation |
As we move up in our careers, mentoring, coaching, and sponsorship become essential career-leveraging relationships to obtain success. The hour workshop will discuss what career-minded individuals need to consider for their own personal and career growth; define the nuances among Mentoring, Coaching, and sponsorship; identify when to best utilize them for particular growth opportunities; and how to identify and establish the right relationship fit. Participants will learn how to create a relationship circle, which is an actionable and adoptable plan for career development. The author will discuss from her personal experience how she developed and utilize these learning to navigate through her own career.
| Feb 24, 2016 | Interleaved direct bandpass sampling for software defined radio/radar receivers Prof. Bernard Levy, Department of Electrical and Computer Engineering, UC Davis |
Slides |
Due to their low hardware complexity, direct bandpass sampling front ends have become attractive for software defined radio/radar applications. These front ends require three elements: a tunable filter to select the band of interest, a wideband sample and hold to acquire the bandpass signal, and finally an analog to digital converter (ADC) to digitize the signal. Unfortunately, due to the overlap of aliased copies of the positive and negative signal spectrum components, if a single ADC is employed, depending on the exact position of the band where the signal is located, it is not always possible to sample a signal of occupied bandwidth B at a sampling rate ?s just above the 2B Nyquist rate. Sometimes, much higher rates are needed. For software radio applications, this represents a significant challenge, since one would normally prefer to use a single ADC with fixed sampling rate to sample all possible signals of interest. A solution to this problem was proposed as early as 1953 by Kohlenberg, who showed that Nyquist rate sampling can be achieved by using time- interleaved sampling, where two sub-ADCs sample the signal at a rate ?s/2 each, but with a relative timing offset d (such that 0 < d < 1 if the offset is measured relative to the sub-ADC sampling period). However, certain offsets are forbidden, since for example d = 1/2 would result in a uniform overall ADC. In this presentation, a method will be described to simultaneously sample and demodulate the bandpass signal of interest. The sampled complex envelope of the bandpass signal is computed entirely in the DSP domain by passing the sub-ADC samples through digital FIR filters, followed by a digital demodulation operation. However, as the quality factor (ratio of the carrier frequency ?c to the signal bandwidth B) of the front-end selection filter increases, the performance of the envelope computation method becomes progressively more sensitive to mismatches between the nominal offset d0 and actual offset d of the two sampling channels. To overcome this problem, a blind calibration technique to estimate and correct mismatches, is presented.
| Feb 18, 2016 | JPEG Emerging Standards Prof. Dr. Touradj Ebrahimi, JPEG Convener, EPFL |
JPEG standardization committee has played an important role in the digital revolution in the last quarter of century. The legacy JPEG format, which became an international standard 21 years ago is the dominant picture format in many imaging applications. This dominance does not seem to slow down when observing that the number of JPEG images uploaded to social networks alone has surpassed 2 billions per day in 2014, when compared to less than a 1 billion the year before. JPEG 2000, which became an international standard 15 years ago, has been the format of choice in a number of professional applications, among which contribution in broadcast and digital cinema are two examples. This talk starts by providing an overview of a recently developed image format to deal with High Dynamic Range content called JPEG XT. JPEG XT has been defined to be backward compatible with the legacy JPEG format in order to facilitate its use in current imaging ecosystem. We will then discuss JPEG PLENO, a recent initiative by JPEG committee to address an emerging modality in imaging, namely, plenoptic imaging. “Pleno” is a reference to “Plenoptic” a mathematical representation, which not only provides color information of a specific point in a scene, but also how it changes when observed from different directions and distances. “Pleno” is also the latin word for “complete”, a reference to the vision of the JPEG committee that believes future imaging will provide a more complete description of scenes well beyond what is possible today. The road-map for JPEG Pleno follows a path that starts in 2015 and will continue beyond 2020, with the objective of making the same type of impact that the original JPEG format has had on today’s digital imaging starting from 20 years ago. Several milestones are in work to approach the ultimate image representation in well-thought, precise, and useful steps. Each step could potentially offer an enhanced experience when compared to the previous, immediately ready to be used in applications. The talk will conclude with an quick overview of two potential standardization initiatives under investigation. The first, referred to as JPEG Privacy & Security facilitates protections and security in legacy JPEG images, such as coping with privacy concerns. The second called JPEG XS puts an emphasis on low latency, low complexity and transparent quality as well as low cost, desirable in a number of applications, including broadcasting and high bandwidth links between devices and displays.
| Jan 21, 2016 | IS ANYBODY OUT THERE? When When Will Earthlings Find ET? Dr. Dan Werthimer, Chief Scientist, Berkeley SETI Research Center |
Slides |
What is the possibility of other life in the universe and can we detect radio and optical signals from other civilizations? Current and future SETI projects, including SETI@home and the new $100-million Breakthrough Prize Foundation Listen project may provide an answer. SETI@home chief scientist Dan Werthimer will describe the rationale for past and future searches, SETI signal processing algorithms, and will show how new technologies are revolutionizing SETI.
 |
 |
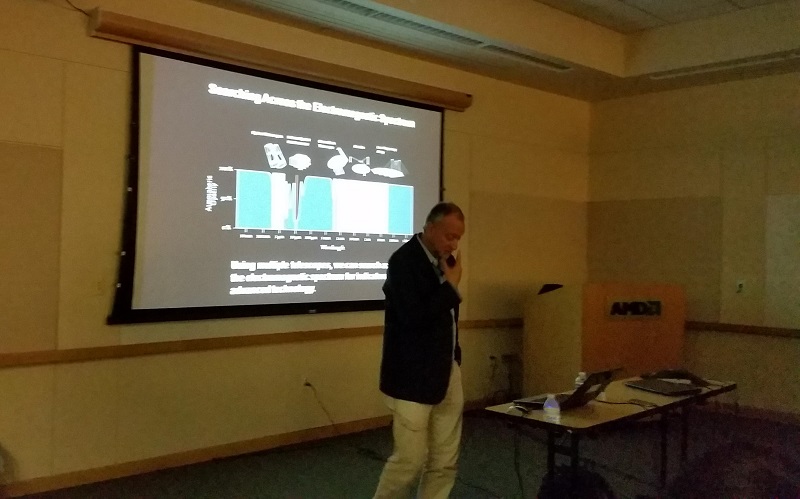 |
 |
| Dec 15, 2015 | Quantization Noise Prof. Bernard Widrow, Department of Electrical Engineering, Stanford University |
The effect of uniform quantization can often be modeled by an additive noise that is uniformly distributed, uncorrelated with the signal being quantized, and uncorrelated over time, being additive white noise having zero mean and mean square of 1/12 q-square, where q is the quantum step size. This simple model is statistical and is based on Nyquist sampling theory applied to the probability density distribution of the signal being quantized. Linear Nyquist theory is applied to precisely describe uniform quantization, which indeed is nonlinear. The simple model applies almost everywhere. This talk surveys the theory behind the simple model and discusses the conditions for its validity. The simple model applies to uniform quantization. However, the theory can be extended to apply to non uniform quantization. This leads to a simple model for floating point quantization. Conditions for the validity of the floating point model will be presented.
| Dec 09, 2015 | Ph.D. Elevator Pitch to Professionals Topics include, Autonomous Driving, Computational Cameras, Scalable Speech Coding, with students from Stanford, UC Santa Cruz and Santa Clara University. |
Looking for new and local talents? Want to keep yourself and your company up-to-date on the latest hot topics and technical contributions in Signal Processing? You can do both by attending the “Ph.D. Elevator Pitch to Professionals” event. The IEEE Signal Processing Chapter of Santa Clara Valley is organizing an event to connect Ph.D. candidate close to graduation and newly graduated Ph.D. to local companies looking for talents and new technologies. A panel of students will explain their Ph.D. contributions and results in the form of elevator pitch, followed by Q&A and a social event to continue the conversations into poster session.
Guest Speaker:
- Alex Acero, President, IEEE Signal Processing Society (Slides)
- David Held, Computer Science Department, Stanford University ( Slides) Video
- Amin Kheradmand, Department of Electrical Engineering, University of California at Santa Cruz ( Slides)
- Koji Seto, Department of Electrical Engineering, Santa Clara University ( Slides) Video
 |
 |
 |
 |
| Nov 18, 2015 | Multi-Robot Adaptive Navigation Dr. Christopher Kitts, Director of Robotic Systems Laboratory, Santa Clara University |
Slides |
Adaptive navigation is the process by which a vehicle determines where to go based on information received while moving through the field of interest. Adaptive sampling is a specific form of this in which that information is environmental data sampled by the robot. This may be beneficial in order to save time/energy compared to a conventional navigation strategy in which the entire field is traversed. Our work in this area focuses on multi-robot gradient-based techniques for the adaptive sampling of a scalar field. To date, we have experimentally demonstrated multi-robot gradient ascent/descent as well as contour following using both wheeled land rovers as well as automated marine surface vessels. In simulation we have verified controllers for ridge descent / valley ascent as well as saddle point detection and loitering. Together, these capabilities establish a set of control primitives that will ultimately allow us to efficiently explore large scale scalar fields. In this talk, we will describe our techniques and present some of our initial experimental results achieved through field operation of our multi-robot systems. 
| Nov 17, 2015 | Rate-distortion of sub-Nyquist sampled processes Alon Kipnis, PhD Candidate, Stanford EE Department |
Consider the task of analog to digital conversion in which a continuous time random process is mapped into a stream of bits. The optimal trade-off between the bitrate and the minimal average distortion in recovering the waveform from its bit representation is described by the Shannon rate-distortion function of the continuous-time source. Traditionally, in solving for the optimal mapping and the rate-distortion function we assume that the analog waveform has a discrete time version, as in the case of a band-limited signal sampled above its Nyquist frequency. Such assumption, however, may not hold in many scenarios due to wideband signaling and A/D technology limitations. A more relevant assumption in such scenarios is that only a sub-Nyquist sampled version of the source can be observed, and that the error in analog to digital conversion is due to both sub-sampling and finite bit representation. This assumption gives rise to a combined sampling and source coding problem, in which the quantities of merit are the sampling frequency, the bitrate and the average distortion.
In this talk we will characterize the optimal trade-off among these three parameters. The resulting rate-distortion-sampling frequency function can be seen as a generalization of the classical Shannon-Kotelnikov-Whittaker sampling theorem to the case where finite bit rate representation is required. This characterization also provides us with a new critical sampling rate: the minimal sampling rate required to achieve the rate-distortion function of a Gaussian stationary process for a given rate-distortion pair. That is, although the Nyquist rate is the minimal sampling frequency that allows perfect reconstruction of a band-limited signal from its samples, relaxing perfect reconstruction to a prescribed distortion allows sampling below the Nyquist rate while achieving the same rate-distortion trade-off.
| Nov 05, 2015 | Scalable Approaches to New Large-Scale Neuroscience Dr. Alyson “Allie” Fletcher, Assistant Professor of Electrical Engineering at UC Santa Cruz |
Recent technological advances offer unprecedented possibilities for observing and manipulating neural activity. Characterizing the structure of neural circuits is a fundamental problem in brain science, however, unraveling the connectivity and interactions among populations of neurons remains a daunting challenge. In this talk, I address two problems: learning the neural response in retinal ganglion cells, and the estimation of large neuronal networks from calcium imaging data. Utilizing a general computationally scalable framework for estimation of large dynamical structured nonlinear systems, the approach significantly improves over existing methods in both computational cost and performance. This methodology offers provable guarantees in consistency and convergence and is applicable across a wide variety of settings.
 |
 |
| Oct 15, 2015 | Gathering Light Dr. Rajiv Laroia, co-founder & CTO, light.co |
Slides |
With digital cameras in every cell phone, everyone is a photographer. But people still aspire to the better zoom, the lower noise, and the artistic bokeh effects provided by the digital SLR cameras, if only these features were available in as convenient and light-weight a package as a cell phone or a thin compact camera. Traditional high-end cameras have a big lens system that enables those features, but the drawback is weight, bulk, and inconvenience of carrying and switching lenses. In this talk, we discuss an alternative approach of using a heterogenous array of small cameras to provide those features, and more. Light’s camera technology combines prime lenses that provide an optical zoom equivalent of 35mm, 70mm, and 150mm lenses. Small mirrors allow reconfiguring the cameras to select the right level of zoom and field of view. This talk describes the architecture of this flexible computational camera.
 |
 |
| Sep 24, 2015 | Android TV Product & Technical Overview Sascha Prueter, Google |
This talk gives an overview of the Android TV platform and it’s support of OTT devices, SmartTVs and PayTV STBs. It will cover the core platform build blocks as well as describe customization possibilities and describe some of TV specific API layers that have been added to Android specifically for the TV space.
| Sep 03, 2015 | Optical Character Recognition for Most of the World’s Languages Dr. Ashok C. Popat, Research Scientist, Google |
Much of interpersonal communication is linguistic, and people exchange linguistic information primarily through speech and through graphical symbolic representation of speech utterances, i.e., writing, printing, typing, etc. In the modern digital age we can represent written communication as sequences of bits grouped into Unicode points, a means which is capable of representing many if not most of the world’s extant languages. But much of the world’s recorded information is still in visual rather than digital Unicode form; it is in books, newspapers, manuscripts, and letters; on post-its, whiteboards, street signs, or video captions. It may also be in the form of a gesture on a touch pad or mobile phone screen, to allow an alternative method of text entry than a keyboard. The conversion of all of these representations to Unicode for use in the digital world is generally known as Optical Character Recognition (OCR). How might an OCR system be designed to handle all of the world’s languages? I’ll explain some challenges that make this nontrivial and describe an approach we’re exploring at Google.
| Aug 19, 2015 | Scene Understanding in the Era of Deep Learning Dr. Jitendra Malik, Prof. Dept. of EECS, University of California, Berkeley |
Slides |
Multilayer neural networks trained with stochastic gradient descent on large labeled datasets have recently been shown to be remarkably good features for computer vision. This is the fourth generation of features in the fifty year history of the field, starting with edges and corners (1960s-1990s), linear filters such as Gaussian derivatives, Gabors, Haar wavelets (1990s), and orientation histograms such as SIFT and HOG (2000s). However, it is not the case that the field has to be reinvented with each new generation of features. Insights from the past of computer vision, and the even longer tradition in human visual perception, retain relevance across these choices. For example, I have been arguing for some time now about the importance of the interaction between recognition, reconstruction and re-organization. In this view, recognition ofobjects is reciprocally linked to re-organization, with bottom-up grouping processes generating candidates, which can be classified using top down knowledge, following which the segmentations can be refined again. Recognition of 3D objects could benefit from a reconstruction of 3D structure, and 3D reconstruction can benefit from object category-specific priors. I will show results on several such problems in my talk, typically using features derived from “deep learning”. The work was done in collaboration with various students and postdocs at Berkeley, and almost all the papers have been posted on arXiv, in case you are interested in more details.
 |
 |
 |
| Aug 06, 2015 | Real-world Audio Source Separation Dr. Gautham J. Mysore, Senior Research Scientist, Adobe Research |
Slides |
Audio source separation algorithms aim to take a recording of a mixture of sound sources as an input and provide the separated sources as outputs. This is useful for a number of applications such as denoising in the presence of complex noises, processing individual instruments in a mixture, automatic karaoke, extracting dialogue from old films to provide a higher quality soundtrack, and upmixing mono recordings to multi-channel recordings. Algorithmically, this is an ill-posed and challenging problem. However, by making use of easily available high level information, generic training data, and user interaction, we can greatly constrain the problem. In this talk, I will discuss a number of techniques that use such constraints with the goal of performing real-world audio source separation.
Link to the open source interactive source separation editor: https://isse.sourceforge.net/
 |
 |
 |
| Jun 03, 2015 | Computational Imaging: From Photons to Photos Dr. Peyman Milanfar, Scientist, Google Research |
Slides |
Fancy cameras used to be the exclusive domain of professional photographers and experimental scientists. Times have changed, but even as recently as a decade ago, consumer cameras were solitary pieces of hardware and glass; disconnected gadgets with little brains, and no software. But now, everyone owns a smartphone with a powerful processor, and every smartphone has a camera. These mobile cameras are simple, costing only a few dollars per unit. And on their own, they are no competition for their more expensive cousins. But coupled with the processing power native to the devices in which they sit, they are so effective that much of the low-end point-and-shoot camera market has already been decimated by mobile photography. Computational imaging is the enabler for this new paradigm in consumer photography. It is the art, science, and engineering of producing a great shot (moving or still) from small form factor, mobile cameras. It does so by changing the rules of image capture – recording information in space, time, and across other degrees of freedom – while relying heavily on post-processing to produce a final result. Ironically, in this respect, mobile imaging devices are now more like scientific instruments than conventional cameras. This has deep implications for the future of consumer photography. In this technological landscape, the ubiquity of devices and open platforms for imaging will inevitably lead to an explosion of technical and economic activity, as was the case with other types of mobile applications. Meanwhile, clever algorithms, along with dedicated hardware architectures, will take center stage and enable unprecedented imaging capabilities in the user’s hands.
 |
 |
| May 21, 2015 | Perceiving Graphical and Pictorial Information via Hearing and Touch Dr. Thrasyvoulos N. Pappas, Northwestern University/LLNL |
Slides |
We explore the use of hearing and touch for conveying graphical and pictorial information to visually impaired people. The main idea is that the user actively explores a two-dimensional layout consisting of one or more objects with the finger on a touch screen. The objects are displayed via sounds and raised-dot tactile patterns. The finger acts as a pointing device and provides kinesthetic feedback. The touch screen is partitioned into regions, each representing an element of a visual scene or graphical display, and each modality a different aspect of the layout. A key element of our research is the use of spatial sound to facilitate the active exploration of the layout. We use the head-related transfer function for rendering sound directionality and variations of sound intensity or tempo for rendering proximity. Our research has addressed object shape and size perception, as well as the perception of a 2-D layout of simple objects (dots). We have also considered the rendering of a simple scene layout consisting of objects in a linear arrangement, each with a distinct tapping sound, which we compare to a “virtual cane.” Subjective experiments with visually-blocked subjects demonstrate the effectiveness of the proposed approaches.
 |
 |
 |
| May 07, 2015 | Scale-space Processing for Light Field Cameras Dr. Ivana Tosic, Senior Research Scientist, Ricoh Innovations, Corp. |
Recent development of hand-held plenoptic cameras has brought light field acquisition into a range of consumer, industrial, biomedical and medical 3D imaging applications. As light fields record both spatial and angular information of light, their high dimensional structure is notably different from traditional 2D images. Because of this, many established image processing and computer vision algorithms become suboptimal and we have to revisit fundamental signal processing approaches and adapt them to light fields. I will show how scale-space analysis, one of the most widely applied frameworks in computer vision today, can be extended to the case of light fields. This new theory involves the construction of Light field scale-and-depth (Lisad) spaces, which are parametrized both in terms of scale of objects recorded by a light field and in terms of objects’ depth. Such scale-invariant 3D analysis of light fields opens the door to novel computer vision algorithms for plenoptic cameras, out of which I will present two: dense depth estimation and 3D keypoint detection.
Reference Papers
“3D keypoint detection by light field scale-depth space analysis”
I Tosic, K Berkner; Image Processing (ICIP), 2014 IEEE International Conference on, 1927-1931
“Light Field Scale-Depth Space Transform for Dense Depth Estimation”
I Tosic, K Berkner; Computer Vision and Pattern Recognition Workshops (CVPRW), 2014 IEEE
“In Vivo Middle Ear Imaging with a Light Field Otoscope”
N Bedard, I Tosic, L Meng, A Hoberman, J Kovacevic, K Berkner; Bio-Optics: Design and Application, BW3A. 3
“Light Field Otoscope”
N Bedard, I Tosic, L Meng, K Berkner; Imaging Systems and Applications, IM3C. 6
 |
 |
 |
| Apr 08, 2015 | Signal Processing and Communication Challenges for the Internet of Energy Prof. Anna Scaglione, Dept. Electrical and Computer Engineering, Arizona State University |
Slides |
In this talk we will discuss signal processing models of the behavior of electric appliances that can support the smart electric power grid. An ecosystems of Electric Vehicles, Smart Thermostats and Smart Lighting will allow customers to interact with the market of electricity directly, optimizing the customer preferences while better exploiting the variable production from renewable energy, from distributed “prosumers” and centralized plants alike. The opportunities for good are immense but there are several challenges. Unlike the internet, which is managed in a decentralized fashion, power systems are large vertically integrated infrastructures and, thus, the interaction between market forces is hampered by the curse of dimensionality. We will discuss the issue of sifting through big data to decide the schedule and closing the loop on a large number of transactions. While the grid is already coping with significant vulnerabilities as is the Internet of Energy can significantly expand the reach of malicious cyber-attacks. We will touch upon the issue of cyber-security and privacy that arise in general with the Internet of Things and with the Internet of Energy in particular.
Reference Papers
“Reduced-Order Load Models for Large Populations of Flexible Appliances”
Alizadeh, M.; Scaglione, A.; Applebaum, A.; Kesidis, G.; Levitt, K., Power Systems, IEEE Transactions on , vol.PP, no.99, pp.1,17
“Dynamic Incentive Design for Participation in Direct Load Scheduling Programs,”
Alizadeh, M.; Yuanzhang Xiao; Scaglione, A.; van der Schaar, M., Selected Topics in Signal Processing, IEEE Journal of , vol.8, no.6, pp.1111,1126, Dec. 2014
“A Scalable Stochastic Model for the Electricity Demand of Electric and Plug-In Hybrid Vehicles,”
Alizadeh, M.; Scaglione, A.; Davies, J.; Kurani, K.S., Smart Grid, IEEE Transactions on , vol.5, no.2, pp.848,860, March 2014 doi: 10.1109/TSG.2013.2275988
 |
 |
 |
| Mar 05, 2015 | Perceptual Audio Coding: An Overview of Basic Principles and Current Standards Dr. Marina Bosi, Consulting Professor, Stanford University |
Slides |
Who would have guessed twenty years ago that teenagers and everybody else would be clamoring for devices with MP3/AAC (MPEG Layer III/MPEG Advanced Audio Coding) perceptual audio coders that fit into their pockets? As perceptual audio coders become more and more part of our daily lives, residing within DVDs, mobile devices, broad/webcasting, electronic distribution of music, etc., a natural question to ask is: what made this possible and where is this going? This talk, presented by one of the developers who helped advance the field of perceptual audio coding, will provide a tutorial on the technology employed in perceptual audio coding and a brief overview of past and current standard development.
 |
 |
| Feb 17, 2015 | The Human Intranet – Where Swarms and Humans Meet Dr. Jan M. Rabaey, Professor, UC Berkeley |
There is no question about it – the Internet of Things (IoT) is happening as we speak. It is radically transforming the information technology platform, and providing an extremely high bandwidth channel between the cyber world (as represented by the Cloud) and the physical and biological world in which we live. The evolution is quite foundational as for the first time it allows for the engineering of systems that tightly interweave the “real” physical and the “imaginary” cyber worlds, often blurring the boundary between the two.
Yet, the IoT concept on itself conjures a picture of a static, internet-centric organization, in contrast to the dynamic and organic nature of many of the cyber-{physical, biological} applications we envision. In such an environment, which we have dubbed the “Swarm”, applications would form by opportunistically marshaling the resources that are available to them at a given time and place. The Berkeley Ubiquitous Swarm Lab is developing a broad range of technologies essential to make the Swarm vision come to reality.
Some of most compelling application domains of the Swarm relate to how humans interact with the world around it and the cyberworld beyond, as well as their fellow human beings and themselves. While the smartphone has already introduced a fundamental change, most of our interactions are still funneled through a limited set of means (such as displays, headphones, keyboards, touch panels) integrated in a single device. The Swarm has the potential to change all of this. Envision instead a “Human Intranet”, that harvests the capabilities of all the devices we carry around us, on us, or inside us, to create a single open and integrated platform, opening the door for true innovation and creativity. In this presentation, some of the true opportunities, challenges and limitations of the swarm and human intranet vision will be addressed.
| Feb 11, 2015 | Current State of Physically Modeled Musical Instruments on Handheld Mobile Devices Pat Scandalis, CTO/CEO, moForte.com |
Handheld mobile computing devices are now ubiquitous. These devices are powerful, connected and equipped with a variety of sensors. Their pervasiveness has created an opportunity to realize parametrically controlled, physically modeled, virtual musical instruments. moForte Inc was founded to develop a line of sonic and musical applications for handheld devices. We developed “moForte Guitar” which is an application for mobile devices that models the guitar family of instruments and enables everyone to experience what its like to play these instruments. We will provide a brief history of physically modeled musical instruments and the platforms that these models have been run on. We will also give an overview of what is currently possible on handheld mobile devices.
| Jan 15, 2015 | Hebbian-LMS Learning Algorithm Dr. Bernard Widrow, Professor of Electrical Engineering, Emeritus, Stanford University |
Slides |
Hebbian learning is widely accepted in the fields of psychology, neurology, and neurobiology. It is one of the fundamental premises of neuroscience. The LMS (least mean square) algorithm of Widrow and Hoff is the world’s most widely used adaptive algorithm, fundamental in the fields of signal processing, control systems, pattern recognition, and artificial neural networks. These are very different learning paradigms. Hebbian learning is unsupervised. LMS learning is supervised. However, a form of LMS can be constructed to perform unsupervised learning and, as such, LMS can be used in a natural way to implement Hebbian learning. Combining the two paradigms creates a new unsupervised learning algorithm that has practical engineering applications and may provide insight into learning in living neural networks.
 |
 |
 |
 |
| Dec 04, 2014 | Signal Processing-Based Technology Entrepreneurship: Chips, Algorithms, and Startups Distinguished Lecturer: Prof. Andrew C. Singer, University of Illinois at Urbana Champaign |
Technology commercialization and entrepreneurship are synonymous with engineering in a wide array of contexts, from academic programs at universities, to funding initiatives at the National Science Foundation and discussion of the central role of engineering in the economic future of America by the National Engineering Forum. In this talk, I will discuss the role of engineering entrepreneurship and technology commercialization as a key driver to our economy and as a tremendous source of interesting problems and opportunities for the signal processing community. In the first half of the talk, I will draw on my experience as Director of the Technology Entrepreneur Center at the University of Illinois over the last decade, and discuss the evolution of technology entrepreneurship as a central focus of engineering programs at Illinois and across the country. In the second half of the talk, I will discuss how signal processing played a critical role in a number of startup companies, including my experience in two that emerged from my research group at Illinois. These include an optical semiconductor company that was the first to employ DSP-enhanced receivers for 10Gbps optical communications, leading to the world’s fastest implementation of the Viterbi algorithm; and at the other end of the spectral extreme, an underwater acoustic communications company commercializing the first video-capable deep-sea wireless modems for the oil and gas industry. These two companies were driven by signal processing solutions to some of the most challenging digital communications channels on the planet.
 |
| Nov 12, 2014 | Intelligent Personal Assistants and Signal Processing Challenges Dr. Asli Celikyilmaz, Senior Scientist, Natural Language Understanding, Microsoft |
Following the rapid proliferation of mobile devices, especially smart phones, multimodal virtual personal assistant (VPA) applications such as Apple Siri, Microsoft Cortana and google Now started to emerge. With the advances in speech recognition, language understanding, and machine learning coupled with client-side capabilities coming with larger screens that enable multi-touch displays and server-side capabilities based on cloud computing, these applications have begun to move beyond conventional simple command/control based speech applications. One of the core technologies in a VPA system is understanding what the users are saying, called as spoken language understanding (SLU). In the last decade, a variety of practical goal-oriented spoken dialog systems have been built for limited domains, employing “targeted” SLU capabilities. Given an utterance, SLU in dialog systems extracts predefined semantic information from the output of an automatic speech recognizer (ASR). This semantic information usually contains the intent of the user and associated arguments (slots), matching the back-end capabilities. The dialog manager (DM) then determines the next machine action given the SLU output. In this talk I highlight some of the technical challenges and research efforts for multimodal virtual personal assistant applications, especially focusing on spoken language understanding and dialog aspects, pointing out issues and opportunities in this area.
 |
| Oct 20, 2014 | Video Processing at YouTube Dr. Anil Kokaram, Tech Lead, YouTube/Google |
Like many streaming video enterprises, YouTube relies on a core pipeline of transcoding and video DSP which has evolved dramatically since YouTube was first established. This talk reviews some of the key aspects of the pipeline and highlights some recent developments in the treatment of partner content as well as 4K.
| Oct 08, 2014 | Signal Processing Applications: Expanding our World, Bringing Us Closer – A Historical Perspective Dr. John Treichler, IEEE Fellow, Raytheon |
Many amazing pieces of technology have come out of Silicon Valley over the past 60 years. To some it may appear that they arrived into the marketplace full-blown and complete, but in fact almost all of them had their roots in an application for which there was no reasonable or affordable solution at the time. This presentation explores the evolutional path followed by most of them, from very expensive, barely-working Hero experiment to reliable low cost commercial product. This is illustrated with examples that started with national defense needs, and then, with the introduction of ever improving semiconductors and digital signal processing (DSP), have turned into common place commercial products. From these examples a pattern becomes clear which can be reasonable expected to extend well into the future.
 |
| Sep 24, 2014 | Information Theory and Signal Processing for the World’s Smallest Computational Video Camera Dr. David G. Stork, Rambus Fellow, Rambus Labs |
We describe a new class of computational optical sensors and imagers that do not rely on traditional refractive or reflective focusing but instead on special diffractive optical elements integrated with CMOS photodiode arrays. Images are not captured, as in traditional imaging systems, but rather computed from raw photodiode signals. Because such imagers forgo the use of lenses, they can be made unprecedentedly small-as small as the cross-section of a human hair. In such a computational imager, signal processing takes much of the burden of optical processing done by optical elements in traditional cameras, and thus information theoretic and signal processing considerations become of central importance. In fact, these new imaging systems are best understood as information channels rather than as traditional image forming devices. As such such systems present numerous challenges in information theory and signal processing: How does one optimize the effective electro-optical bandwidth given the constraints of optical components? What is the tradeoff in computational complexity and image quality or other metrics? What is the proper electro- optical representation and basis function set? The talk will end with a list of important research opportunities afforded by this new class of computational imager.
| Sep 23, 2014 | The computational array camera Dan Lelescu, Pelican Imaging |
Slides |
Computational cameras have become ubiquitous in the research community (though not yet in the consumer space), as various architectures are being considered for creating output features that are not possible, or very difficult to obtain with “traditional” cameras. Computational cameras reflect our desire to capture more information about the world around us through imaging (whether in the visible spectrum or not), and to exploit that information in applications that enhance our interaction with the imaged scene. In this context, we will introduce the topic by discussing the definition and a taxonomy of computational cameras. Some examples of trade-offs that computational cameras make to achieve their unique features, will be discussed. The unifying view that computational cameras can be seen as imaging codecs will be advanced, with the “encoder” (e.g., modified optics) acting in well-defined ways on the imaged scene signal, and the attendant tightly-coupled digital processing being the “decoder” in charge of producing the output features of interest. This concept will be exemplified using various kinds of computational cameras. In this general framework, we will then follow with a review of a computational array camera developed by Pelican Imaging, Inc. Some of the capabilities of this array camera will be illustrated.
| Sep 18, 2014 | Control of Multi-Robot Systems: From Formations to Human-Swarm Interactions Distinguished Lecturer: Prof. Magnus Egerstedt, Georgia Institute of Technology |
The last few years have seen significant progress in our understanding of how one should structure multi-robot systems. New control, coordination, and communication strategies have emerged and, in this talk, we discuss some of these developments. In particular, we will show how one can go from global, geometric, team-level specifications to local coordination rules for achieving and maintaining formations, area coverage, and swarming behaviors. One aspect of this concerns how users can interact with networks of mobile robots in order to inject new, global information and objectives. We will also investigate what global objectives are fundamentally implementable in a distributed manner on a collection of spatially distributed and locally interacting agents.
| Sep 10, 2014 | Breast CT Scanner Imaging Advancement and Evolution at UC Davis Prof. John M. Boone, University of California Davis Medical Center, Sacramento |
Slides |
The breast tomography project began at the University of California Davis around the year 2000. Since then, for prototype breast CT scanners have been designed, fabricated, integrated, and tested clinically. This process, over 600 women have had breast CT scans on these platforms. The breast CT systems at UC Davis made use of existing hardware such as an x-ray, x-ray tube and generator, and motor/encoder systems, but all other aspects were designed in-house, fabricated at a local machine shop under contract, and assembled and integrated in our laboratory. In this presentation, an overview of the hardware evolution will be presented, outlining the improvements in image quality through each prototype scanner. A thorough discussion of the image processing requirements of the breast CT system will also be discussed, including image correction methods, image preprocessing (prior to reconstruction) for scatter correction and Hounsfield Unit calibration, cone beam reconstruction, and image analysis methods including post-reconstruction flat fielding, and the assessment of quantum and anatomical noise of the breast.
 |
| Aug 14, 2014 | Bayesian Methods for Sparse Signal Recovery and Compressed Sensing IEEE SPS Distinguished Lecturer: Dr. Bhaskar D. Rao, Ericsson Endowed Chair and Professor, University of California, San Diego |
Slides |
Compressive sensing (CS) as an approach for data acquisition has recently received much attention. In CS, the signal recovery problem from the observed data requires the solution of a sparse vector from an underdetermined system of equations. The underlying sparse signal recovery problem is quite general with many applications and is the focus of this talk. The main emphasis will be on Bayesian approaches for sparse signal recovery. We will examine sparse priors such as the super-Gaussian and student-t priors and appropriate MAP estimation methods. In particular, re-weighted l2 and re-weighted l1 methods developed to solve the optimization problem will be discussed. The talk will also examine a hierarchical Bayesian framework and then study in detail an empirical Bayesian method, the Sparse Bayesian Learning (SBL) method. If time permits, we will also discuss Bayesian methods for sparse recovery problems with structure; Intra-vector correlation in the context of the block sparse model and inter-vector correlation in the context of the multiple measurement vector problem.
 |
 |
| Aug 06, 2014 | IEEE Tutorial on LDPC Decoding, VLSI Architectures and Implementations Dr. Ned Varnica [Marvell Semiconductor], Dr. Kiran Gunnam [Violin Memory] |
LDPC codes are now being used in Hard disk drive read channels, Wireless (IEEE 802.11n/ IEEE 802.11ac, IEEE 802.16e WiMax), 10-GB, DVB-S2, and more recently in Flash SSD. Tutorial’s target audience is system engineers and design engineers. Tutorial has two parts, first module is focused on LDPC Decoding and second module is focused on VLSI Architectures and Implementations. IEEE Standard draft LDPC codes for Flash memories also will be covered.
| Jul 09, 2014 | Digital Signal Processing: Core Differentiation in Early Stage Companies Dr. Steve Goldberg, Partner, Venrock |
After the bursting of the first tech bubble of 2000, the world of early-stage venture capital made a strong move away from most things that were capital intensive or those projects that appeared to require scientific breakthroughs to succeed. Additionally, part of the recent decline in Cleantech investing was attributable to perceived excessive science and/or engineering risk. It appeared, for a time, that science and engineering might be playing a declining role in value creation in early-stage technology companies. The good news is that signal processing, algorithm development, and embedded systems have roared back in importance in early-stage venture investing. New markets have burst onto the scene, including big data, data analytics, UAV’s, robotics, augmented reality, gesture recognition, and nanosatellites, among others, that not only depend on signal processing but are often the core product differentiation. This talk will review the state of the industry of early-stage technology investing as it relates to signal processing, algorithm development, and embedded systems.
 |
| May 14, 2014 | Production & Post-Production Video Compression Standards Delivering Awesome Images for Television & Digital Cinema Edward Reuss, Independent consultant |
Slides |
Video compression standards for production and post-production have different requirements than compression standards for consumer applications. Consumer compression standards, such as H.264 and H.265, emphasize very high compression ratios and low-cost decoder solutions in order to satisfy millions of users with relatively small storage and transmission capabilities. Production and post-production systems emphasize image quality and ease of editing. This presentation contrasts these different requirements and presents several video compression standards designed for television and digital cinema professional content management workflows. An analysis of the image processing algorithms used by each of these, along with some of the non-technical constraints (Intellectual property, marketing, etc.), demonstrates their relative advantages and disadvantages.
 |
| Mar 17, 2014 | DSP – Whence It Came and Where It is Going; A Tour for Non-Specialists Shiv Balakrishnan, Mobility Semiconductors |
This is a review of the field of Digital Signal Processing (DSP) and is intended for those who do not necessarily use DSP on a daily basis. We look at the key drivers for the field such as FFT and Digital Filters and show how the evolution of these techniques served growing numbers of important application areas such as communications and multimedia. The rise of programmable Digital Signal Processors (also known, somewhat confusingly, as DSP’s) is chronicled along with the differences between fixed point and floating point implementations. The impact of DSP on general purpose compute architectures is described, along with the growth in hardware implementations both in IC technology and FPGA. We also look at DSP as a market and see how that view has significantly fragmented by application area in recent times. The impact of DSP on analog design is touched upon as well as describing a number of newer application areas for DSP technology.
| Jul 23, 2012 | Defying Nyquist in Analog to Digital Conversion IEEE Distinguished Lecturer: Dr. Yonina Eldar, Dept. of Electrical Engineering, Technion — Israel Institute of Technology |
The famous Shannon-Nyquist theorem has become a landmark in the development of digital signal processing. However, in many modern applications, the signal bandwidths have increased tremendously, while the acquisition capabilities have not scaled sufficiently fast. Consequently, conversion to digital has become a serious bottleneck. In this talk a new framework for sampling wideband analog signals at rates far below that dictated by the Nyquist rate will be presented. The focus will be both on the theoretical developments, as well as on actual hardware implementations and considerations that allow realization of sub-Nyquist samplers in practice. Applications to a variety of different problems in communications, bioimaging, and signal processing will also be described.
| Dec 13, 2010 | Make3D: Learning 3D Models from a Single Still Image Ashutosh Saxena, Assistant Professor, Computer Science Department, Cornell University |
We consider the problem of converting a standard 2D digital picture into a 3D model. This is a challenging problem, since an image is formed by a projection of the 3D scene onto two dimensions, thus losing the depth information. We take a supervised learning approach to this problem, and model the scene depth as a function of the image features. We show that, even on unstructured scenes of a large variety of environments, our algorithm is frequently able to recover accurate 3D models. (See https://make3d.cs.cornell.edu ) We then look at the problem of combining our cues such as stereo (for stereo cameras) or parallax (for videos) for producing 3D views from 2D views.
The last few decades have seen great progress in tackling each of these problems in isolation. Only, recently have researchers returned to the difficult task of considering them jointly. We consider learning a set of related models in such that they both solve their own problem and help each other. Our method requires only a limited black box interface with the models, allowing us to use very sophisticated, state-of-the-art classifiers without having to look under the hood. We then apply our methods to robotics applications: (a) vision-based navigation: obstacle avoidance for autonomously driving a small electric car and autonomously flying aerial vehicles, and (b) personal robots, where we develop learning algorithms for robot manipulation. This enables our robot to perform tasks such as open new doors, clear up cluttered tables, and unload items from a dishwasher.
| Nov 08, 2010 | Making 3D Printing Ideas Real: A Demo and Talk J. R. Warmkessel, Founder Bay Area MakeBot users group |
The 3D printer was first designed for rapid prototyping in the commercial arena. With the advances in technology, and the significant drop in price, this technology is now available to enthusiasts and hobbyists. The RepRap project is an open source 3D Printer, designed for at home use. A RepRap 3D printer heats ABS or PLA plastics and extrudes it in thin layers to build the final product. There are multiple implementations of the RepRap project, with the best-known version being the MakerBot CupCakeprinter. The CupCake printer is a complete kit that includes everything that a user needs to build and use the printer at home. The 3D printers use standard CNC (Computer Numeric Control) phases to design and print the products. CNC has three phases: CAD, CAM, and Cut. CAD, or Computer Aided Design, is the process by which parts and assemblies are designed. The final product of this phase is a software file, often STL (Stereo Lithography). Common CAD software includes SolidWorks, Rhino, and GoogleSketchup. CAM, or Computer Aided Machining, is process of converting the STL file into set of sequential commands that serve as instructions for the printer (called G-code). The MakerBot uses Skeinforge CAM software. Cut is process by which the machine (in this case, the 3D printer) creates the final product through execution of the G-code. The MakerBot uses ReplicatorG Cut software. Discussion will include the benefits of 3D printing, and of using the RepRap project for 3D printing, the pitfalls, problems, and limits of 3D printing, and finally, the future of 3D printing and the RepRap project.
| Oct 21, 2010 | Tutorial on “Status of knowledge on non-binary LDPC decoders Prof. David Declercq (ENSEA in Cergy-Pontoise) |
In this tutorial, the iterative decoding techniques for non-binary LDPC codes will be presented, both from the theoretical aspects of Belief Propagation and its analysis, and from more practical aspects of efficient implementation. In a first part, the main difference between iterative BP decoding of binary and non-binary LDPC codes will be highlighted. Then, in a second part, the solutions proposed in the literature to reduce the complexity of non-binary decoders, both for memory storage and computational burden reduction, will be presented. Some directions of research and development about non-binary decoders will be discussed. Finally, the outstanding advantages of generalized non-binary decoders on clustered graphical models of several error correcting codes will be presented.
| Sep 13, 2010 | Principles of Canesta CMOS 3D Time of Flight Systems Cyrus Bamji, Co-founder and CTO of Canesta |
Canesta’s 3D electronic perception technology allows electronic devices to perceive their environment by providing accurate 3D information about the world around them. Canesta’s 3D time of flight sensor is a massively parallel LIDAR on a single CMOS chip. When coupled to a light source such as a LED, laser or VCSEL, each 3D pixel on the chip provides independent distance information to objects in the field of view of the device. The basic operating principle of Canesta’s CMOS phase-based pixel technology is described. An analysis of the factors influencing sensor performance is presented and an explanation of how to build a time of flight system that meets the requirements of a given application is provided. Applications for 3D time of flight systems are described and advantages of these systems over competing methods are discussed. Canesta’s latest high resolution 3D camera will be demonstrated.
| Jun 14, 2010 | Next Generation 3D Television – Demo at HDI-US Inc Ingemar Jansson, CEO of HDI and Edmund Sandburg, CTO of HDI |
We are in the early days of 3D television and 3D movie proliferation. While there are many competing technologies for 3D capture and rendering, it is the consumer home where the winners will be voted in or out. Almost all the TV makers are releasing 3D television models with various degrees of technical sophistication, price points and viewing comfort. In this June meeting, we will explore the question of ultimate 3D viewing comfort.
HDI Ltd. is a research and design firm that has perfected laser-driven 3D projection display technology with greater than high-definition resolution. Among the first products to emerge after more than three years of intensive R&D, HDI Ltd.’s laser-driven 100-inch diagonal 2D/3D Switchable Dynamic Video Projection Display delivers a stunningly superior 2D image, with a 50% greater resolution than today’s digital cinemas, and derives its greater-than-high definition stereoscopic 1920 x 1080p 3D image quality from two RGB laser-illuminated Liquid Crystal on Silicon (LCOS) micro display imagers. At full 1080p HD, the HDI Ltd. screen refreshes at 360 fields per-second on each eye, the fastest refresh rate on any mass produced television or projector. HDI’s 2D/3D Switchable Dynamic Video Projection Display, at a mere 10-inches thick, draws 80% less power than existing 2D flat screen plasma monitors of the same size, and HDI projection displays are anticipated to have a street price potentially 60% less than current 2D flat screen plasma displays. HDI Ltd. has completely eliminated the adverse effects, such as migraines, dizziness, and nausea, long associated with substandard 3D display technology. HDI Ltd. delivers the most immersive, comfortable, and natural 3D viewing experience in the world with low-cost and lightweight proprietary polarized glasses. Steve Wozniak, co-founder of Apple Computers, calls HDI Ltd., “Without a doubt, the best demonstration of 3D technology I have ever seen.” Technology journalist Richard Hart states, “The smoothest yet, and smoothness means no headaches.” And Sean Portnoy of ZDNet.com, wrote, “We could be looking at a Holy Grail of sorts for the next generation of television.”
| May 10, 2010 | Electronic Tagging and Managing Congestion in Electric Power Transmission Systems Farrokh Albuyeh, OATI |
Beginning in 1996, with the Federal Energy Regulatory Commission’s (FERC) orders 888 and 889, the electric power industry began the task of unbundling generation of electricity from transmission, and Independent System Operators were created to manage the operation of the transmission grid to provide equal access to all generation facilities and power producers. At the same time an Open Access Same-Time Information System (OASIS) was created to help with the management and reservation of transmission facilities to accommodate energy transactions across the north American interconnected transmission system. Soon it became apparent that the resulting increase in energy transactions was exercising the transmission facilities in way not seen before, with the Control Area operators observing congestion in their transmission systems without knowing the source or the cause. The main problem arose from the fact that transmission reservations were made based on agreed upon Contract Paths which had little or no correlation with the flow of power on Physical Paths as dictated by the laws of physics. To deal with this problem, and electronic tagging, or e-tagging, system was designed and implemented to provide Control Area operators with information on all energy transactions that flowed through their systems. In addition, an Interchange Distribution Calculation (IDC) system was developed to calculate the physical impact of individual transaction on the power grid and transmission equipment for use in support of Transmission Loading Relief (TLR) procedures that were developed to mitigate congestion in transmission systems. Over the years e-tagging has evolved to serve as a mechanism for the capture and the management of all data related to energy transactions not only to support congestion management but also to support tracking and management of Renewable Portfolio Standard (RPS) and for Greenhouse Gas (GHG) emission monitoring and tracking, among other things. In this presentation, we will provide an overview of the evolution and the functionality of e-tagging and will discuss the use of e-tagging and IDC in managing transmission grid congestion in North America.
| Apr 12, 2010 | Pervasive Learning – Diagnosis and Management of Production Systems Julia Liu, Palo Alto Research Center |
Modern production systems are optimized for productivity, but component faults or deterioration often occur in practice. Diagnosis and health management of a production system are thus important. They can be formulated as a statistical inference problem, where observations are obtained to update the knowledge regarding component conditions. Prior work often puts the production system in halt and switch to trouble-shooting/learning mode to gather observations; other work uses passive observations during production. In this talk, we introduce the novel paradigm of pervasive learning, which constructs informative production plans that simultaneously achieve production goals while uncovering additional information. We show two concrete examples of pervasive learning (diagnosis of single-fault systems, and continuous model adaptation) and explain the information criteria that are used to select production plans.
| Mar 15, 2010 | An overview of various physical and MAC layer research and developmental issues in 4G cellular systems Joydeep Acharya, Wireless Systems Research Lab (WSRL), Hitachi America Ltd |
Slides |
Cellular networks are experiencing a rapid growth in terms of services provided and customer base. To enable new features such as faster data rate, better support for video and real time applications, there needs to be fundamental changes in the underlying radio level technology. This talk highlights the key features of some of these technologies. It also explains how multiple companies after doing R&D, meet and discuss their results which ultimately leads to the evolution of a generation of cellular systems.
| Feb 10, 2010 | Developer Opportunities with CLEAR WiMAX 4G David Rees and Allen Flanagan, Clearwire |
Mobile WiMAX as provided by Clearwire (the CLEAR network) is also available from Sprint, Comcast, and Time Warner, under a reseller/ MVNO agreement in the United States. These 4G wireless networks represent an opportunity for a new generation of products and services that take full advantage of mobile broadband capabilities. Clearwire understands that the true value of 4G WiMAX will be realized through new products and services, and with this in mind is focused on enabling 3rd party applications, services and devices for the CLEAR network. At what promises to be a very informative meeting, Clearwire’s David Rees and Allen Flanagan will provide an overview of the CLEAR network, nation-wide rollout, and device plans. They will provide details on CLEAR’s Innovation Network program and how Silicon Valley developers can get discounted aircards and free 4G network access through 2010 to develop and test their 4G ideas. Dave and Allen will also walk through the available and planned platform and device services that CLEAR will be providing including location, network session information, connection management, activation, and provisioning. Some of the use cases of these services will be described, including proactive video optimization and location-enabled services. A lively panel session will follow these presentations. The speakers and moderator will address the role of the application developer in making mobile WiMAX and CLEAR successful. Clearwire’s future plans for enabling 3rd party applications and devices will be discussed along with competition from 3G and 3.5G networks. Looking further out, we’ll get Clearwire’s views on IEEE 802.16m (WiMAX 2.0) vs. LTE.
| Jan 11, 2010 | Distributed Systems Health Management Sankalita Saha |
As we move towards increasingly autonomous machines, it is important to understand how machines fail and if catastrophic failures can be prevented or mitigated. An important approach to tackle this problem is condition based maintenance (CBM) where various components, sub-systems and hierarchically the whole system are monitored to detect and diagnose faults and maintenance is scheduled accordingly. A key facilitating technology for this approach is prognostics, which refers to the determination of remaining useful life (RUL) of a component or a system once a fault has been detected and diagnosed. This concept is gradually gaining importance for efficient health management of systems ranging from simple machines like gearboxes to complex components like power electronics to large-scale engineered systems like automobiles, aircraft and spacecrafts. The field of prognostics and health management (PHM) comprises multiple complex problems each replete with daunting challenges. However, recent advances in sensor technologies have given us a handle on tackling some of these problems satisfactorily. In this talk, an overview of prognostics and health management will be presented first, after which a distributed wireless sensor network based architecture for such health management systems will be discussed.
| Dec 11, 2009 | Next-generation mobile WiMAX (802.16m) Update Dr. Jong-Kae (J.K.) Fwu, Intel Corporation |
Slides |
To meet the tremendous demand and growth for mobile Internet and wireless multimedia applications, the IEEE 802.16 Working Group Task Group m (TGm) has been developing a next-generation mobile WiMAX system (4G) since early 2007. The next-generation mobile WiMAX system, as a new amendment of the IEEE 802.16 standard (i.e., IEEE 802.16m), will provide enhancements including higher throughput/mobility, higher user capacity, and lower latency while maintaining full backward compatibility with the existing mobile WiMAX systems (802.16e). This presentation provide a high level tutorial on the prominent technical features and design of IEEE 802.16m and the ongoing technologies in the evolution toward the next-generation WiMAX network. It is focused on the general overall 16m system and particularly PHY related perspectives
| Nov 09, 2009 | Digital Compensation of Dynamic Acquisition Errors at the Front-End of High-Performance A/D Converters Dr. Parastoo Nikaeen, Netlogic Microsystems |
In A/D converter applications such as wireless base stations, IF sub-sampling is an attractive method for minimizing component count and system cost. By applying this method, one or more steps of down-conversion are removed from the receiver path and some of the analog front-end signal processing functions can be moved to the digital domain. In such a solution, the ADC’s linearity at high input frequencies becomes a critical issue. Despite the use of a dedicated track-and-hold amplifier (THA), nonlinearities in the circuit’s input network often introduce dynamic errors that limit the performance of the ADC at high input frequencies.
In this talk, I will present a digital enhancement scheme that is specifically tailored to remove high frequency distortion caused by the dynamic nonlinearities at the sampling front-end of ADCs. The basic concept of digital compensation here is to apply the inverse nonlinear function to the digital output of the ADC in order to minimize its error over the desired frequency range. Conceptually, a nonlinear system with memory can be modeled with a Volterra series. However, the inverse Volterra series becomes very complex as the order of nonlinearity and memory in the system increases and it requires intensive computational power that is impractical even in today’s fine-line technology. Our proposed algorithm uses information about sources of nonlinearities and judicious modeling to simplify the digital post processing scheme. Applying the method to a 14-bit, 155-MS/s ADC provides > 83 dB SFDR up to f_in = 470 MHz. The post-processing block is estimated to consume 52 mW and occupy 0.54 mm^2 in 90-nm CMOS.
| Oct 12, 2009 | Detection of Information Flow and Anonymous Networking IEEE SPS Distinguished Lecturer: Prof. Lang Tong, School of Electrical and Computer Engineering, Cornell University |
In a wireless network, transmission activities can be easily monitored using simple devices. Given the record of transmissions from a set of nodes, one may be able to assertain whether these nodes are engaged in some networking operations. While the content of a wireless transmissions can be protected by cryptographical techniques, the acts of transmission may reveal crtical information about network operations such as routing and multicasting. In this talk, we consider two related problems. The first is the problem of flow detection: given observations from a set of traffic sensors, to what extent can the presence of an information flow be detected? We present results on the fundamental limit of detectability. The second problem is anonymous networking: to what extent can we hide an information flow. Here we use information theoretic measures to characterize the tradeoff between anonymity vs. network throughput.
| Sep 21, 2009 | Low-Voltage Oversampling Analog-to-Digital Conversion Dr. Bruce A. Wooley (Robert L. and Audrey S. Hancock Professor of Engineering, Dept. of E.E.) Stanford University |
Through the exchange of resolution in time for that in amplitude, oversampling methods are now widely used to enable the realization of high-resolution analog-to-digital converters in scaled CMOS VLSI technologies. So-called oversampling modulators combine coarse quantization at sampling rates well above the Nyquist rate with feedback and subsequent digital signal processing to avoid the need for precision analog circuits. Such modulators were originally conceived in the mid-twentieth century in the form of delta modulators, which digitize the rate of change of a signal, rather than the signal itself. However, noise-shaping modulators that directly encode the signal proved to be a more robust approach and have subsequently come into widespread use. In particular, cascades of inherently stable sigma-delta (or, equivalently, delta-sigma) modulators are an efficient means of extending the dynamic range of oversampling converters that are largely immune to both analog circuit imperfections and fundamental stability concerns. This presentation begins with an overview both architectural and circuit issues associated with the design of noise-shaping modulators, and then presents examples of some approaches to their implementation under increasingly severe constraints on power dissipation and supply voltage.
| Sep 17, 2009 | Monitoring video quality inside a network SPS Distinguished Lecturer: Dr. Amy Reibman, AT&T Labs |
Slides |
As broadband access connectivity becomes more prevalent, more users are streaming video over the Internet, or watching video that has been transmitted over a network. However, the best-effort service model and shared infrastructure of most networks means that network impairments (such as delays, jitter, congestion, and loss) may affect viewing experiences. Network service providers are increasingly interested in measuring the quality of the video that is provided on their network. This can aid in monitoring compliance of service-level agreements (SLAs) between Internet Service Providers (ISPs), hosting centers, and content providers; alert operators to potential performance problems; and help in root-cause analysis and debugging. We consider the problem of evaluating the quality of transported, compressed video from the perspective of a network service provider. Traditional video quality metrics require original and decoded pixels to be available. However, neither are easily available inside the network. Therefore, we have developed no-reference techniques that estimate visual quality, relying only on (potentially lossy) bitstreams available inside the network. In this talk, we present an overview of the problem with measuring video quality in the network and present two quality metrics: one for broadcast MPEG-2 video and the other for streaming video over the Internet.
| Jun 22, 2009 | Adaptive Learning in a World of Projections Prof. Sergios Theodoridis, Technical University of Athens, Greece |
Slides |
The task of parameter/function estimation has been at the center of scientific attention for a long time and it comes under different names such as filtering, prediction, beamforming, curve fitting, classification, regression. In this talk, the estimation task is treated in the context of set theoretic estimation arguments. Instead of a single optimal point we are searching for a set of solutions that are in agreement with the available information, which is provided to us in the form of a set of training points and a set of constraints. The goal of this talk is to present a general tool for parameter/function estimation, under a set of convex constraints, both for classification as well as regression tasks, in a time adaptive setting in (infinite dimensional) Reproducing Kernel Hilbert spaces (RKHS). Each algorithm consists of a sequence of projections, of linear complexity with respect to the number of unknown parameters. Our theory proves that the algorithm converges to the intersection of all (with a possible exception of a finite number of) the convex sets, where the required solution lies. The work has been carried out in cooperation with Kostas Slavakis and Isao Yamada.
| Mar 25, 2009 | WiMAX Update: IEEE 802.16m and WiMAX future Hassan Yaghoobi, Intel Corporation |
Slides |
The purpose of this talk is to provide an update on WiMAX technology. The presentation provides a brief update on productization from WiMAX Forum, standardization update on IEEE 802.16m/Rev2 and IMT-Advance. On WiMAX Forum side, an update on Release 1.5 and FDD enablement will be provided. On the standardization side, an update on IEEE 802.16m status is provided through coverage of System Requirement, System Description, Evaluation Methodology and the Standard Amendment projects. As IEEE 802.16m is a candidate for IMT-Advance, a brief section of presentation is dedicated to provide an update on IMT-Advance and status of submission of 802.16m and WiMAX Forum Release 2.0 to ITU.
| Feb 09, 2009 | The Scalable Communication Core: A Multi-Core Reconfigurable Wireless Baseband Prototype Dr. Anthony Chun, Intel Corporation |
Over the past few years, there has been a rapid increase in the number of wireless standards that have been deployed around the world. To address the consumer demand for ubiquitous communications and computing with low power and area, we have developed the Scalable Communications Core (SCC), a flexible baseband processor for wireless protocols that consists of a heterogeneous set of coarse-grained, programmable accelerators connected via a packet-based 3-ary 2-cube Network-on-Chip (NoC). We will present an overview of the architecture, describe how protocols are mapped to the architecture and discuss a recently completed a prototype test chip that was taped out in a 65nm process and validated for WiFi and WiMAX protocols.
| Feb 07, 2009 | SPS SCV Workshop on FPGAs for Digital Signal Processing Applications Dr. Craig Stephens, Dr. Sami Khuri, Dr. Byung-Jun Yoon, and Dr. Ru-Fang Yeh |
| Jan 12, 2009 | Dynamic Graphs Prof. Dragoslav Siljak, Santa Clara University |
Dynamic graphs are defined in a linear space as a one-parameter group of transformations of the graph space into itself. Stability of equilibrium graphs is formulated in the sense of Lyapunov to study motions of positive graphs in the nonnegative orthant of the graph space. Relying on the isomorphism of graphs and adjacency matrices, a new concept of dynamic connective stability of complex systems is introduced. A dynamic interaction coordinator is added to complex interconnected system to ensure that the desired level of interconnections between subsystems is preserved as a connectively stable equilibrium of the overall system despite uncertain structural perturbations. It is shown how the coordinator can be designed to adaptively adjust the interconnection levels in order to assign a prescribed state of the complex multi-agent system as a stable equilibrium point. The equilibrium assignment is achieved by the action of the coordinator which solves an optimization problem involving a two-time-scale system; the coordinator action is slow compared to the fast dynamics of the agents. Polytopic connective stability of the multi-agent systems with a coordinator is established by the concept of vector Lyapunov functions and the theory of M-matrices.
| Dec 08, 2008 | Exploiting Real World Channels for Increased Capacity Ernest Tsui and Xiaoshu Qian |
Slides |
Directional channel models are becoming accepted channel models for an increasing number of standards that require MIMO processing. We will cover exactly what these directional channels are, how they are modeled, and how they relate to reality. Then we will discuss the impact of the models on MIMO performance and link budgets.
| Nov 03, 2008 | Design Techniques and CMOS Implementation of Low Noise Amplifier (LNA) Prof S. S. Jamuar |
The rapid growth of portable RF communication systems in various standards has led to the demand for one chip to cover several standards such as WCDMA, WLAN, GSM etc. This leads to the stringent requirements for the RF front-end to cover a large range of different carrier frequencies for all standards. A receiver system consists of the following circuits: a low noise amplifier, mixer, voltage-controlled oscillator (VCO), intermediate frequency (IF) amplifier and filters. The low noise amplifier (LNA) is typically the first active stage for the RF front-end. Its main function is to amplify low signals without adding noise, thus preserving the signal-to-noise ratio (SNR) of the system at low power consumption. Many tradeoffs are involved in designing the LNA such as noise figure (NF), linearity, gain, impedance matching and power dissipation. Therefore, proper LNA design considerations and techniques are crucial in today’s communications technology. This lecture places an emphasis on improved design techniques for the low noise amplifier (LNA). DC biasing techniques, impedance matching techniques, noise matching and stability analysis will be discussed. Voltage mode design and current mode design techniques will be elaborated. Variable gain low noise amplifier design techniques will also be discussed. All the design techniques and simulations presented in the tutorial will be based on EDA tools.
| Oct 20, 2008 | Multichip module packaging and its impact on architecture Dr. Hubert Harrer, Senior Technical Staff Member, Server and Technology Group, IBM |
The presentation compares the system packaging and technologies of IBM’s latest system z high end servers. Starting from the z900, the system design change towards a blade-like architecture will be explained. The latest system generation z9 has achieved a doubling of the multiprocessor performance compared to the z990 system by maximizing its CPU configuration in combination with increasing the speed of the interconnections. This MCM technology is the key enabler for the high bandwidths between processor chips and the cache chips. The glass ceramic module has accomplished this challenge within the 102 layers resulting in a total wiring length of 545m. The increase of bandwidth requirements for the packaging will be compared for the last generations. Also the complex board and card technology of the second level packaging will be discussed. The cooling of the system is being done with a modular refrigeration unit (MRU), which cools the processor chips down to 45C. This low temperature ensures highest reliability and reduced leakage current of the chips. An air cooled backup mode at a lower frequency ensures that the system does not go down in case of an MRU fail. The MCM has been designed for a maximum power of 850W during nominal operation and 1200W in case of the air-cooled backup mode. The presentation will focus on the electrical design methodologies for high end servers like power delivery concepts, signal integrity methodologies and power integrity designs for delivering such high currents.
| Sep 22, 2008 | Past and Future of Digital Watermarking Dr. Ton Kalker, Hewlett-Packard Labs |
Slides |
The term ‘Digital Watermarking’ refers to methods and techniques for adding auxiliary data to multimedia signals. In the mid nineties digital watermarking was heralded as the solution for all copyright and copy protection issues: in one form or another the opening paragraph of many papers contained the reasoning ‘copyright protection is important, therefore we need watermarking’. However, today, more than 10 years later, we find very few actually deployed applications of digital watermarking. In this talk we will try to explain why digital watermarking has not lived up to its expectations, as well making an educated guess about what the future of digital watermarking will be.
| Aug 30, 2008 | SPS SCV Workshop on Bio-informatics and Bio-signal Processing Dr. Craig Stephens, Dr. Sami Khuri, Dr. Byung-Jun Yoon, and Dr. Ru-Fang Yeh |
 |
(1) Molecular Biology Basics, Dr. Craig Stephens, Santa Clara University
https://www.scu.edu/cas/biology/staffandfaculty/craig-stephens.cfm |
 |
(2) Computational Methods in Bioinformatics, Dr. Sami Khuri, San Jose State University |
 |
(3) Signal Processing Models and Algorithms for RNA Sequence Analysis, Dr. Byung-Jun Yoon, Texas A&M University, College Station, TX |
 |
(4) Biostatisitcs: Statistical analysis of bio-data , Dr. Ru-Fang Yeh, University of California San Francisco |
| Jun 02, 2008 | Enhancing Image Fidelity through Spatio-Spectral Design for Color Image Acquisition, Reconstruction, and Display Keigo Hirakawa, Postdoctoral Research Associate, Harvard University, Department of Statistics |
Slides |
In the first part of the talk, we consider extending an image denoising problem to the problem of missing or incomplete pixel values—either due to mechanical designs or distortions. In the context of wavelet-based image processing, missing or incomplete pixels pose a particularly difficult challenge because none of the wavelet coefficients can be observed. In this talk, a unified framework for coupling the EM algorithm with the Bayesian hierarchical modeling of transform coefficients is presented. This empirical-Bayes strategy offers a statistically principled and extremely flexible approach to a wide range of pixel estimation problems including image denoising, image interpolation, super resolution, demosaicking.
In the second part of the talk, we consider the “throughput” of color imaging systems. Pixel values are typically sensed or displayed via a spatial subsampling procedure implemented as a color filter array—a physical construction whereby only a single color value is measured or displayed at each pixel location. Owing to the growing ubiquity of acquisition and display devices, much of recent work has focused on the implications of such arrays for subsequent digital processing, including in particular the canonical demosaicking task of reconstructing a full color image from spatially subsampled and incomplete color data acquired under a particular choice of array pattern. In contrast to the majority of the acquisition and display literature, we consider here the problem of color filter array design and its implications for spatial reconstruction quality. We prove the sub-optimality of a wide class of existing array patterns, and provide a constructive method for its solution that yields robust, new panchromatic designs implementable as subtractive colors.
| May 12, 2008 | Content-Adaptive Efficient Resource Allocation for Packet-Based Video Transmission Prof. Aggelos K. Katsaggelos, Department of EECS, Northwestern University |
Supporting video communication over lossy channels such as wireless networks and the Internet is a challenging task due to the stringent quality of service (QoS) required by video applications and the many channel impairments. Two important QoS characteristics for video are the degree of signal distortion and the transmission delay. Another important consideration is the cost associated with transmission, for example, the energy consumption in the wireless channel case and the cost for differentiated services in the Internet (with DiffServ) case. In this presentation we consider the joint adaptation of the source coding parameters, such as the quantization step-size and prediction mode, along with the physical layer resources, such as the transmission rate and power. Our goal is to provide acceptable QoS while taking into account system constraints such as the energy utilization. We discuss a general framework that allows a number of “resource/distortion” optimal formulations for balancing the requirements of different applications. We conclude the presentation with some of the grand opportunities and challenges in designing and developing video communication systems.
| Apr 14, 2008 | RF Systems Design :Fundamental Theory and WiMAX Examples Tony Liu, Ph.D. |
The rapidly growing wireless communication market creates a high demand for radio frequency (RF) transceivers. While low-cost, low-power, and small form factors are the necessary requirements for modern RF system, achieving reliable and good quality communication links is definitely an essential design factor in wireless communications. To accomplish a successful RF transceiver design meeting all these requirements, not only circuit designers but also system engineers need to closely work together to achieve the goal. This presentation is aimed to give an introduction of RF system design including wireless communication overview, basic concepts in RF design, RF transceiver architecture, analog-to-digital converter, and a WiMAX RF system design example. Some fundamental RF system design questions, e.g. how much RF gain, how many dB of dynamic range, how many bits of ADC, what RF transceiver architecture we need, are illustrated in a WiMAX receiver example.
| Mar 10, 2008 | Digital Fingerprinting for Multimedia Forensics Prof. Min Wu, Institute of Advanced Computer Studies, University of Maryland, College Park |
Technology advancement has made multimedia content widely available and easy to process. These benefits also make it easy to make unauthorized duplication, manipulation, and redistribution of multimedia content, prompting the need of multimedia forensics research to facilitate evidence gathering in digital world. Embedded digital fingerprinting is one of the emerging forensics technologies. A unique ID that serves as a digital fingerprint to represent a receiving user is inserted into the content, and the fingerprinted content is then delivered to the user. When some copies are leaked or misused, the authority will be able to use these embedded fingerprints to trace back to the culprits. For multimedia data, digital fingerprints can be put into the content using conventional robust embedding techniques, which are typically concerned with surviving attacks mounted by an individual. Advances in communications and networking have made it easy for adversaries to work together to generate a new version based on their individual copies. These so-called collusion attacks provide adversaries with a cost-effective way to remove the fingerprints and circumvent the traitor-tracing mechanism. In this talk, I will present our recent research on anti-collusion fingerprinting for multimedia data. Through jointly considering the encoding, embedding, and detection of fingerprints, our techniques can help collect digital-domain evidence and pinpoint to the sources of leak among millions of users. Applications of such multimedia forensic tools range from military and government operations to piracy deterrence in Hollywood and other entertainment industry. If time permits, I will also give a brief introduction on non-intrusive forensic analysis that explores intrinsic traces to complement the embedded fingerprints in determining the origin and processing history of digital multimedia data.
| Feb 11, 2008 | Simplified Fast Motion Estimation: Simplified and Unified Multi-Hexagon Search (SUMH) with Context Adaptive Lagrange Multiplier (CALM) Prof. Nam Ling, Department of Computer Engineering, Santa Clara University |
Video |
Fast motion estimations are especially important to speed up the time-consuming encoding processes for H.264 video encoding. In this talk, we first present our simplified fast motion estimation method, called Simplified and Unified Multi-Hexagon Search (SUMH), that produces a significant speed-up as compared with today’s fast motion estimations, yet encounters only a small PSNR degradation when compared to that of full search. In addition, we present a novel method to refine the Lagrange multiplier, called Context Adaptive Lagrange Multiplier (CALM), for rate-constrained motion estimation. Both our methods were recently adopted into the H.264/MPEG-4 AVC video coding international standard (including the text document and the JM reference software). Our SUMH is based on two principles, partial distortion search (PDS) and dual-halfway-stop (DHS) algorithms. PDS generally produces less video quality degradation of the predicted images than those of conventional fast block matching algorithms (BMAs). However, the speedup gain of PDS algorithms is usually limited. In this talk, we present an enhancement over a normalized PDS (NPDS) algorithm to further reduce block matching motion estimation complexity and improve video fidelity. The novelty of our algorithm is that, in addition to the halfway-stop technique in NPDS, a dual-halfway-stop (DHS) method, which is based on a dynamic threshold, is proposed so that block matching is not performed against all searching points. The dynamic threshold is obtained via a linear model utilizing already computed distortion statistics. An adaptive search range mechanism based on inter block distortion further constrains the searching process. Experimental results show that our proposed method reduces the encoding time by about 55% on the average when compared to those of the state-of-the-art methods, with similar rate-distortion performances. Our SUMH algorithm, making use of DHS-NPDS, consists of two parts, an integer-pel fast search and a sub-pel fast search. To extend motion estimation further, we propose a new simple and efficient method to adjust Lagrange multipliers based on the context (CALM), which improves the accuracy for the detection of true motion vectors as well as the most efficient encoding modes for luma, which are used for deriving the motion vectors and modes for chroma. Simulation results show that the chroma bit rates can be reduced by 4.36% and 4.80% (on the average) for U- and V- chroma components, respectively, when compared with that of the recent JM reference software. In addition, the coding efficiency improvement is comparable to the more complicated rate-distortion optimized (RDO) mode decision techniques.
| Jan 07, 2008 | An Open Baseband Processing Architecture for Future Mobile Terminal Design Prof. Willie W. Lu, U.S. Center for Wireless Communications (USCWC) |
Slides |
The future wireless and mobile communications will be shifted from the traditional transmission-specific technology to the interface-specific technology to be able to converge with the computer system architecture. As Prof. Willie Lu firstly pointed out in 2004 World Wireless Congress and Stanford University, “The future radio is first, a computer, then an Open Wireless Architecture (OWA) terminal”. The OWA technology offers an optimal solution to open up the wireless platform from physical layer to the middle layers and support the service-oriented architecture and infrastructure in the upper layers of the future mobile phone development. Working with Google Android open application platform and other industry leading solutions, OWA cores simplify the different radio transmission technologies (RTTs) into interface-based hardware/software modules which are portable, extensible and transferable among various system platforms. Furthermore, OWA makes base-band signal processing of different common air interfaces to be extremely simple and performance-efficient, and enables the future mobile phone basically open for any wireless transmission standards. This talk introduces an open wireless architecture (OWA) terminal design, focusing on the open baseband processing platform to support different existing and future wireless communication standards through the multi-dimensional open baseband processing modules with open interface parameters and baseband management systems. The talk describes multi-layer open system architecture to maximize the system flexibility and minimize the terminal power consumption, so as to provide an integrated and converged next generation wireless and mobile communication terminal system. As a case study, we will also introduce the next generation iPhone platform supporting WiMax, WiFi, WCDMA, GSM and TD-SCDMA powered by OWA technology.
White paper on the talk’s topic
| Dec 10, 2007 | Re-Live the Movie “The Matrix”: From Harry Nyquist to Image-Based Rendering Prof. Tsuhan Chen, Department of Electrical and Computer Engineering, Carnegie Mellon University |
In recent years, the field of visual computing has observed a convergence of image processing, computer vision, and computer graphics. Multiview imaging represents one central theme of the convergence. Now widely used in applications ranging from special effects (e.g., in the movie “The Matrix”) to 3D object tracking, multiview imaging has become an essential tool for creating informative visualization and effective 3D analysis. In this talk I will introduce recent research on sampling, reconstructing, and relighting multiview images. I will present our mobile camera array, composed of 48 mobile platforms each carrying a video camera. These mobile cameras respond to 3D scenes and position themselves for the most effective 3D analysis. While discussing the mechanism for sampling the 7-dimensional plenoptic function, we will reveal the connection between multiview imaging and the Sampling Theorem discovered by Harry Nyquist almost 80 years ago!
| Nov 12, 2007 | Efficient Techniques for MPEG-2 to H.264 Video Transcoding Dr. Jun Xin, Xilient Inc. |
Slides |
MPEG-2 has become the primary format for broadcast video since being developed in the early 1990’s. The new video coding standard, referred to as H.264/AVC, promises the same quality as MPEG-2 with about half the data rate. Since the H.264/AVC format has been adopted into new storage format standards, such as Blu-ray Disc, and HD-DVD, it is expected that H.264/AVC decoders will appear in consumer video recording systems soon. Certainly, as more high-definition contents become available and the desire to store more contents or to record multiple channels simultaneously increases, long recording mode will become a key feature for future consumer video recorders. To satisfy this need, novel techniques have been developed to transcode MPEG-2 broadcast video to the more compact H.264/AVC format with low complexity. In this talk, transcoding techniques aimed for low-complexity MPEG-2 to H.264/AVC transcoding will be presented. Both intra and inter transcoding architectures and algorithms will be discussed. The key to a successful transcoder design is to take full advantage of the information already available from the MPEG-2 bitstream. Specifically, I am going to talk about efficient motion vector reuse and mode decision algorithms. I will show that the proposed algorithms achieve very good rate-distortion performance with low complexity. Compared with the cascaded decoder-encoder solution, the coding efficiency is maintained while the complexity is significantly reduced.
| Oct 08, 2007 | Overview of Multimedia Signal Processing on Multi-Core Processors Yen-Kuang Chen, Ph.D., Principal engineer at Intel Corporation |
This talk is to give a basic overview of multi-core processors, which represent a major development in computing technology recently. Traditionally, increasing clock frequency is one of the main dimensions for conventional processors to achieve higher performance gains. Today, increasing clock frequency has reached a point of diminishing returns and even negative returns if power is taken into account. Multi-core processors, also known as chip multiprocessors (CMPs), promise a power-efficient way to increase performance and become prevalent in vendors’ solutions, for example, IBM CELL Broadband Engine processors, Intel Core 2 Dual processors, Sun UltraSPARC T1 processors, and so on. Furthermore, placing many powerful computing cores on a single processor opens up a world of important possibilities for next-generation multimedia signal-processing applications and algorithms. Soon we would expect processors with tens or hundreds of cores, e.g., Nvidia Tesla platforms and Intel’s 80-core research prototype. However, the trend of multi-core processors brings a paradigm shift in applications development. In order to fully explore the potential of many-core CPUs, GPUs, and DSPs, researchers and application developers must think about parallelism creatively. This talk will also discuss related challenges in application developments, especially focusing on multimedia signal processing applications.
| Sep 17, 2007 | Transceiver Designs for Multicarrier Transmission Prof. Yuan-Pei Lin, National Chiao-Tung University, Taiwan |
The multicarrier transceiver has found applications in a wide range of wired or wireless transmission channels. It is typically called DMT (discrete multitone) for wired DSL (digital subscriber loops) applications such as ADSL (asymmetric DSL) and VDSL (very high-speed DSL), and called OFDM (orthogonal frequency division multiplexing) for wireless LAN (local area network) and broadcasting applications such as digital audio broadcasting and digital video broadcasting. For wireless transmission, the channel profile is usually not available to the transmitter. The transmitter is typically channel independent and there is no bit/power allocation. Moreover having a channel independent transmitter is of vital importance for broadcasting applications, where there are many receivers with different transmission paths. In wired DSL applications, the channel does not vary rapidly. This allows the receiver to send channel profile back to the transmitter through a reverse channel.
In this lecture, we consider optimal transceiver design for two cases: (i) channel profile available at the transmitter; (ii) channel profile not available at the transmitter. In the first case, the transmitter is channel independent and the channel dependent part of the transceiver should be only at the receiver. The optimal transceiver that minimizes bit error rate rate subject to the same transmission power will be designed. For the second case, bit and power allocation can be used to exploit the disparity among the subchannel noise variances. The optimal transceiver that minimizes transmission power subject to the same transmission bit rate and the same bit error rate will be derived. Substantial gain can be achieved using the optimal transceiver, especially for moderate number of subcarriers. The popularity of system-on-chip (SOC) integrated circuits has led to an unprecedented increase in test costs. This increase can be attributed to the difficulty of test access to embedded cores, as well as long test development and test application times. This talk will present test resource partitioning techniques that facilitate low-cost SOC test. Topics to be covered include the recent IEEE 1500 standard for testing core-based SOCs and techniques for modular testing of digital SOCs. Test planning methods that involve the use of wrappers and test access mechanisms will be discussed. Test scheduling techniques for the concurrent testing of embedded cores at the SOC level will also be presented. Together, these techniques offer SOC integrators with the necessary means to manage test complexity and reduce test costs.
| Sep 10, 2007 | Overview of WiMax Technology and Evolution Hassan Yaghoobi |
Slides |
Mobile WiMAX technology, based on IEEE 802.16e-2005 standard, was first commercialized in Korea through initial offering of WiBro services in the middle of 2006 and subsequent expansion in early 2007. They are also to be deployed by Sprint by the end of 2007 in US. These deployments are based on WiMAX Forum Mobile System Release 1 profile currently being certified by WiMAX Forum. As the deployments spread around the world, Mobile WiMAX is also evolving to include new technology and to meet new demands. For example, IEEE 802.16 TGj and TGm are currently developing Multi-hop Relay enhancements and the next generation Advanced Air Interface respectively. The purpose of this presentation is to familiarize the audience with an overview of the technology and different evolution projects and provide technical analyses on how these projects support the technology’s evolution target requirements.
| May 21, 2007 | Tesla Roadster: Embedded microprocessors and Design trade-offs! Doug Bourn, Senior Electrical Engineer, Tesla Motors, Inc |
Tesla Roadster, like most modern vehicles, relies on embedded microprocessors for safety and performance. From the anti-lock braking system (ABS) to motor control, firmware-defined functions control all aspects of vehicle behavior. For example, control loops in a dozen microprocessors monitor battery environmental parameters, state of charge, and safety interlocks. Three processors interpret driver inputs from the shifter and accelerator to control motor speed and direction. A fourth processor monitors motor and controller temperatures to modulate power to two blower fans for cooling. Four CAN busses connect these and other vehicle subsystems to gather status and coordinate control functions. This presentation will outline the history of the Tesla Roadster and discuss a few of the design tradeoffs resulting in the decisions made in its implementation.
| Mar 21, 2007 | A Simulation Model for IEEE 802.11n Thomas Paul, Electrical Engineering, Santa Clara University |
In an effort to improve the performance of Wireless LAN (WLAN) devices, the IEEE (Institute of Electrical and Electronics Engineers), in late 2003, formed a task group, TGn, to work on a new specification: 802.11n. The goal was to deliver speeds of at least 100Mbps, which would more than double the existing maximum rate of 54Mbps provided by the 802.11a and 802.11g amendments. Currently, the 802.11n draft (standard still under development) offers rates up to 600Mbps through the use of MIMO (multiple-input, multiple-output) antenna structures. In this presentation, we discuss the signal processing techniques used to achieve these rates over indoor wireless environments. Techniques discussed include space-time coding, channel estimation, beamforming, and MIMO detection, including linear and ML detectors. A simulation model developed using Matlab/SIMULINK implementing the transmitter-receiver system is also presented.
| Feb 12, 2007 | A/D and D/A Converters with Integrated High-speed Compression Al Wegener, CTO, Samplify Systems, Inc |
Various compression methods have become integral components of computer systems (WinZIP), audio distribution (MP3), and video processing (MPEG, H.264). However, effective and efficient compression techniques for high-speed A/D and D/A converters have not been available. This talk describes the Samplify series of algorithms, which provides both lossless and lossy compression of bandlimited, sampled data acquired by A/D converters, or provided to D/A converters, and then further processed by FPGAs or ASICs. Samplify provides a lossless compression mode whose compressed data rate varies, depending on the redundancy present in the signal. Samplify also offers two complementary lossy compression modes, in which users select either a desired compression ratio (such as 2.05:1 or 3.68:1) or a desired dynamic range (such as 65.5 dB). Examples using common, bandlimited signals demonstrate the rate-distortion tradeoffs enabled by the Samplify algorithms. Improved compression ratios can be achieved by combining a training phase, in which the signal’s characteristics are discovered, with a compression phase. The Samplify algorithms require a modest amount of FPGA resources and operate at up to 200 Msamp/sec. Higher sample rates are achieved by instantiating parallel compression and decompression blocks.
| May 12, 2006 | New Directions in Home Theater Systems Victor Ramamoorthy, PhD, Infinite Algorithms |
We are currently on the verge of stepping into exciting new possibilities in home entertainment systems. New insights into human perceptual systems have resulted in improved designs that can
approach our perceptual limits of satisfaction without overload and stress. Fueled by developments in imaging, display, video, audio, and radio technologies, entirely new entertainment designs are emerging. In this talk, we will explore these trends and technologies that support them: Wavelet decomposition ideas have led to very high quality compression designs supporting Digital Cinema. Wave Field Synthesis is driving high definition spatial audio rendering systems. UWB radio technologies promise high data rates in short distances eliminating need for cable connections. High dynamic range imaging is transforming camera systems design. The confluence of these advances portends endless opportunities to innovate and build new products for consumers. Some examples will be illustrated.
| Apr 10, 2006 | Correcting Distortion in Multi-media Audio Terminals Dr. Kevin Lashkari, currently consultant to DoCoMo USA Labs |
Future multimedia terminals such as videophones will be used at almost an arm’s length from the speaker and require high quality sound at high playback levels. Small loudspeakers in mobile devices introduce severe linear and nonlinear distortions into the sound at high sound volumes. To enable high quality multimedia services signal processing methods are needed to compensate for the distortions of the electroacoustic conversion. Conventional approaches use a predistortion filter placed between the audio signal source and the loudspeaker. The predistortion filter is based on the pth order inverse of the Volterra model of the loudspeaker. The p-th order inverse is computationally very intensive and does not result in an exact inverse. A new compensation method based on the exact nonlinear inverse and a novel model of the loudspeaker are introduced. It is shown that the Volterra-Wiener-Hammerstein model of the loudspeaker lends itself to having an exact inverse and is a closer match to the loudspeaker response. An experimental setup involving hardware and software was developed to evaluate the performance of the new techniques as well as those reported in the literature using real loudspeakers and perceptual metrics. The initial results with real loudspeakers are consistent with the predictions and result in significant improvement in the sound quality.
| Feb 13, 2006 | Distributed Wireless Communication: A Shannon-Theoretic Perspective on Fading Multihop Networks Sumeet Sandhu, PhD & Ozgur Oyman, PhD, Communications Technology Lab, Intel |
Distributed communication is an advanced wireless technology that allows cooperative communication by ensembles of wireless devices. Devices located close to the source cooperate by re-encoding and forwarding packets, and devices located close to the destination cooperate by sharing received packets. Such cooperation provides diversity gains against wireless channel impairments such as fading, shadowing and path-loss. It improves performance over and beyond what is possible with traditional point-to-point links in a flexible manner by harvesting diversity in the network. The simplest form of cooperation is a multi-hop network where nodes cooperate by forwarding packets one at a time. We consider a fading multihop network with a single active source-destination pair connected via multiple hops over a row of intermediate relays. We use Shannon-theoretic tools to analyze the tradeoff between energy efficiency and spectral efficiency (known as the power-bandwidth tradeoff) for a simple communication protocol based on time-division decode and forward relaying. It is commonly believed that communication over multiple hops suffers in fading channels due to the worst link limitation. In contrast, our results indicate that hopping can significantly improve the outage behavior over slow-fading networks and stabilize links against random channel fluctuations. We prove that there exists an optimal number of hops that minimizes the end-to-end outage probability. Finally, we provide numerical performance comparisons based on realistic channel models. The talk also covers a more advanced form of cooperation known as virtual MIMO, and it’s advantages as well as distributed communication protocols.
| Dec 12, 2005 | Mobile WiMAX: True Broadband Wireless Enabled Aditya Agrawal, Director of Marketing, Beceem Communications |
The IEEE 802.16e standard which enables standards-based true mobile broadband wireless will be formally ratified by the IEEE in December this year. 802.16e is also popularly known as Mobile WiMAX. This talk will give an overview of the standard, how WiMAX Forum is working to make this standard a globally pervasive technology, and technical information on what makes this standard exciting including the fact that this is the first wireless access standard that is based on OFDMA, has support for multiple antenna techniques like MIMO and beamforming and has advanced MAC layer options to support many users with QoS.
| Jun 13, 2005 | Using Technology to Keep Other Countries Honest John Treichler, Chief Technical Officer, Applied Signal |
This talk presents an historical view of how signal processing technology has been used to provide the intelligence needed to protect nations from one another. Examples from the First World War through the Cold War are used to illustrate the impact that technical intelligence collection can have in the verification of treaties meant to prevent war and, where necessary, in the conduct of war.
| Apr 25, 2005 | How many antennas does it take to get broadband wireless access? – The story of MIMO Professor B. Friedlander, Dept of Electrical Eng, Univ of California at Santa Cruz |
The use of multiple antennas has a long and successful history in Wireless systems. Multiple receive antennas for diversity are standard in cellular and WLAN systems. MIMO systems attempt to improve upon this by the use of multiple antennas at the transmitter as well as at the receiver and by employing sophisticated signal processing to extract additional performance gains. Wireless systems employing MIMO are now available for 802.11 (pre 802.11n) and will be available for other WLAN and cellular systems. Progress is being made in standard body activities on incorporating MIMO into future wireless systems. After decades of research and development the cost of implementing multi-antenna systems has finally fallen to levels where commercial applications of the technology are feasible. As is often the case with a relatively new and promising technology, expectations of performance improvements are high, while the level of understanding of its limitations are low. This talk will explain the basic concepts, the tradeoffs between diversity gain and spatial multiplexing gain. The ability of MIMO to increased throughput and extend the range of current base-stations and access points will be discussed for both fixed and mobile scenarios and for both indoor and outdoor applications from home networking to broadband wireless access Various issues which tend to limit the theoretical performance advantages of MIMO will be addressed including the impact of channel conditions (e.g. small angular spread) and the costs associated with reliable channel estimation.
| Jan 10, 2005 | Converting MATLAB Algorithms to FPGA or ASIC Designs Michael Bohm, CTO, Vice President, AccelChip |
In the DSP domain, MATLAB is the DSL of choice with 97% of DSP design implemented on dedicated DSP processors. MATLAB provides both an efficient system-level verification environment and an efficient path to implementation. Unfortunately, the process of converting MATLAB to “C” code to run on the processor is reaching its limits. A DSP processor’s inherent limitation of serial operation is becoming a bottleneck for advanced high-performance algorithms. To solve this problem, a new methodology must be in place to convert algorithmic MATLAB to a register-transfer language (RTL) that can be used by industry-standard synthesis and verification tools. Companies that use the new methodology will benefit from greater productivity, both in terms of the domain-specific language and from the new breed of best-in-class tools they will enable. This presentation will show the process of taking a MATLAB algorithm down to a silicon representation. It will demonstrate a design style and methodology for implementing this algorithm in either an FPGA or an ASIC.
| Dec 13, 2004 | Reconfigurable Systems Emerge Nick Tredennick, PhD, IEEE Fellow, Fellow of the IEEE, editor of Gilder Technology Report |
As the world shifts from tethered to mobile, reconfigurable systems will emerge. After twenty years of progress, the PC is good enough for most consumers. As PC development becomes less profitable, design emphasis shifts to mobile systems such as digital cameras, MP3 players, and cell phones. Mobile systems change the design goal from cost performance to cost-performance-per-watt. Smaller transistors won’t help because they are too expensive and they leak too much. The microprocessor, which has held back advances in hardware design for thirty years, won’t be the workhorse in mobile systems of the future. Microprocessors and DSPs are unsuitable for mobile systems because instruction-based processing is computationally inefficient and because they use too much energy. Today’s memory components are also unsuitable for mobile systems. New programmable logic devices based on next-generation non-volatile memory will enable efficient reconfigurable systems.
| Nov 08, 2004 | Nonlinear adaptive systems Tokunbo Ogunfunmi, Ph.D, Associate Professor, Dept of Elect Eng, Santa Clara Univ. |
Nonlinear models are the correct models for several naturally-occurring phenomena. Lots of problems encountered in the real world involve noise and distortion due to physical processes that are time varying and nonlinear. These cannot be accurately characterized by linear fixed transfer functions. However, engineers have largely avoided the area of nonlinear systems partly because of the limitations of the analytical tools at the disposal of the engineer and partly because the education of engineers emphasizes linear systems for which there have been a myriad of analytical tools developed over the years. Emergence of new analytical tools and faster computer processing power can now make nonlinear system realizable and usable in practice. This talk, will discuss the application of truncated Volterra model for realizing nonlinear adaptive filters, which presents two major drawbacks namely, no exact method of isolating the individual Volterra operator exists for the measurement of Volterra kernels of a given system and secondly, problem concerns the large eigen-value spread which results in slow convergence speed and large mis-adjustment especially for the gradient-based nonlinear adaptive algorithms. It will be followed by applications of nonlinear adaptive systems based on the nonlinear Wiener model. The particular polynomial to be used is determined by the characteristics of the input signal we’re required to model. The advantages of this method will be discussed with several examples comparing the performance of both methods.
| Sep 13, 2004 | Anytime, Anywhere IP Communications Marthin De Beer, VP & GM, Cisco Systems, Inc |
IP Communications – the convergence of Voice, Video and Data onto a single infrastructure is delivering new opportunities for productivity and improved communications to Enterprise
employees. This same technology is now becoming available to consumer with a host of VoIP services being offered by the likes of AT&T, Vonage and Comcast. This however is only the
beginning of what could be a revolution in the way we work, live, play and learn.
| Jun 14, 2004 | Fortran 95, or Matlab meets C++ Matthew Halfant, PhD, VP Advanced Technology, Genesis Microchip, Inc |
Some years ago I upgraded a Microsoft Fortran compiler from PowerStation 1 to PowerStation 4, hoping to gain the advantage of a true 32-bit memory model. Quite unexpectedly, the upgrade took me from Fortran 77 to something called Fortran 90, and this ultimately proved far more exciting than the “mere” transition from 16 to 32 bits. Fortran 90, and its current successor Fortran 95, breaks with the rigid formatting conventions of earlier Fortran; it introduces dynamic memory allocation, derived data types (“structs”), operator overloading, and other modern language features. Of greatest value to me personally is the array notation, which is very similar to Matlab’s: this allows a natural expression for array operations, which simplifies coding and simultaneously opens the door to high-performance execution on parallel hardware. I’ve chosen this topic because many of my colleagues have had no inkling of this development — at any mention of Fortran they simply visualize the classical dialect and are understandably puzzled at my enthusiasm. This is too good to be a well-kept secret, so I wish to offer an overview of modern Fortran and illustrate, with examples from my own work, how empowering it has been for me.
| Apr 12, 2004 | On the Deployment of the Voice Biometric: Challenges and Best Practices Larry Heck, PhD, Vice President, R&D of Nuance Communications |
Wouldn’t it be great not to have to remember all those PINs we are forced to use for transactions over the telephone? As it turns out, those companies that subject us to PINs would like to get rid of them too. Recent analyst estimates show that approximately 30% of all help desk calls to human agents are for resetting forgotten PINs, costing an average of $20/call and millions per year for large enterprises. The solution is to replace PINs with a biometric: verify people by their physiological or behavioral characteristics (e.g., fingerprints, voice, iris). Comparing biometrics, voice has a number of distinct advantages for securing telephone-based transactions: it leverages existing infrastructure, uses an inexpensive and ubiquitous input device(telephone), and is the most intuitive and least obtrusive biometric. So why is it taking so long for the voice biometric to save us from PINs? In this talk, I will address that question and I will discuss how Nuance has been working hard to make the voice biometric pervasive on the telephone network.
| Mar 08, 2004 | Telephony Speech Recognition Application Testing Zaydoon Jawadi, CEO of CoAssure, Inc |
Self-service automated speech-recognition and DTMF telephony applications provide convenient access to real-time information via the telephone, as well as cut costs by eliminating the need for call center assistance by representative. Application issues can result in customer dissatisfaction and unsuccessful self-service; furthermore, they can cause callers to opt for live agents, undermining the advantages and cost savings expected from the system. Therefore, comprehensive testing is essential for the success of such applications. Prior to deployment and any time hardware or software upgrades, various testing and analysis of functionality and performance need to be conducted. Traditionally, dialog traversal, also called call flow, is verified manually. However, using automation, comprehensive, consistent, repeatable, automated testing can be achieved, along with cost saving.
| Feb 05, 2004 | Speech Technology for Computer Assisted Language Learning (CALL) Yoon Kim, PhD., CEO, NeoSpeech Inc |
The evolution of advanced speech input and output technologies now allow us to explore new possibilities in automated language instruction, where the machine presents students with highly
interactive lessons for acquiring a new language. This talk will provide an overview of the state-of the-art technologies in computer assisted language learning, and introduce several real-world applications. We will also provide an industry-wide overview of how speech technologies are being used now and could be used in the future in the context of language learning applications. Demonstrations of software products and technologies focusing on automated language education will be given to illustrate the power of using speech input/output technology in solving real, specific problems.